CNNでカタカナ文字の分類
MLPでの学習結果と見比べてみる。
hanamichi-sukusuku.hatenablog.com
上記の記事でMLPの簡単なモデルでの結果を出力している。

実行結果

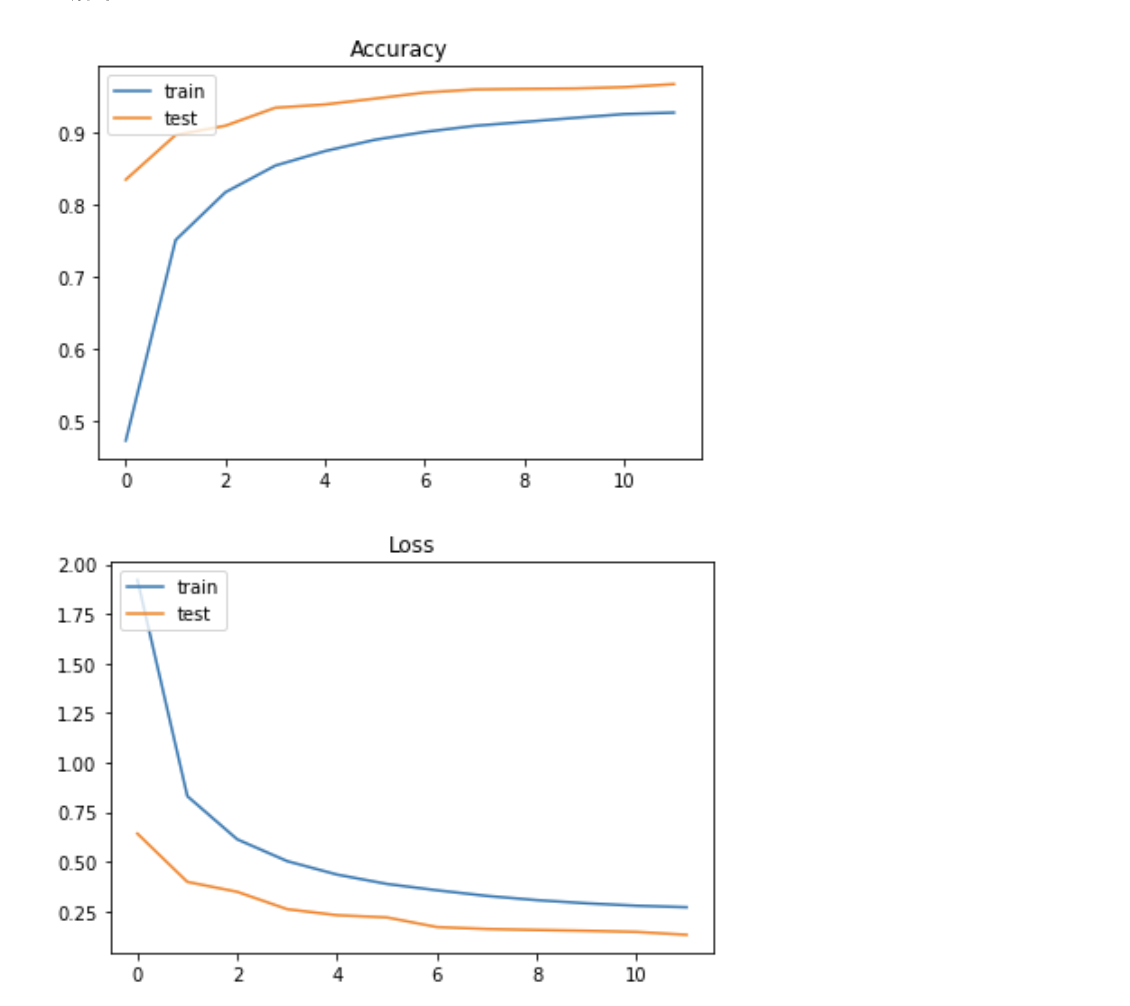
MLPでの評価結果は約90%だったのに対してCNNでの評価結果は約96%と高いものになった。
必要な値の定義と画像データの読み込み
import cv2, pickle
from sklearn.model_selection import train_test_split
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import RMSprop
from keras.datasets import mnist
import matplotlib.pyplot as plt
# データファイルと画像サイズの指定
data_file = "./png-etl1/katakana.pickle"
im_size = 25
out_size = 46 # ア-ンまでの文字の数
im_color = 1 # 画像の色空間/グレイスケール
in_shape = (im_size, im_size, im_color)
# カタカナ画像のデータセットを読み込む --- (*1)
data = pickle.load(open(data_file, "rb"))
im_sizeは今回扱う画像データは25✖️25なので25を定義しておく。
out_sizeはア~ンまでの数の46を定義。モデルの出力レイヤーのユニット数などに使用する。
im_colorはグレースケールのデータなので1を定義。RGB画像の場合は3。
in_shapeは今回のモデルには三次元の配列を扱うので1列の要素を25列持ち、それが25行の三次元配列によって一つの画像が表現されるので25(幅),25(高さ),1(色空間)の三次元の配列に変換する時に使用する。
pickle.load()で画像データ読み込み。
画像データの変形、ラベルデータone-hotベクトル化
y =
x =
for d in data:
(num, img) = d
img = img.astype('float').reshape(
im_size, im_size, im_color) / 255
y.append(keras.utils.to_categorical(num, out_size))
x.append(img)
x = np.array(x)
y = np.array(y)
読み込んだ画像データ(dataは(ラベルデータ,画像データ)このように格納されている)をreshape()で次元を変換する。既に25✖️25のまとまりでデータがループしてくるので25行,25列,1要素の三次元に変換。CNNのモデルを使うのでこの処理が必要。255で割ることで0.0~1.0で表現できるようにしている。
ラベルデータ(num)はkeras.utils.to_categorical()でone-hotベクトル化。46クラスに分類するので第二引数にout_sizeを指定。
学習用、テスト用に分割
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size = 0.2, train_size = 0.8, shuffle = True)
ここでx_train.shapeを実行してみると
(55309, 25, 25, 1)のように表示される。これは、(画像数, 画像幅, 画像高さ, 色数)の次元を持つ配列になっていることを表している。shapeでは各次元毎の要素数を確認することができる。
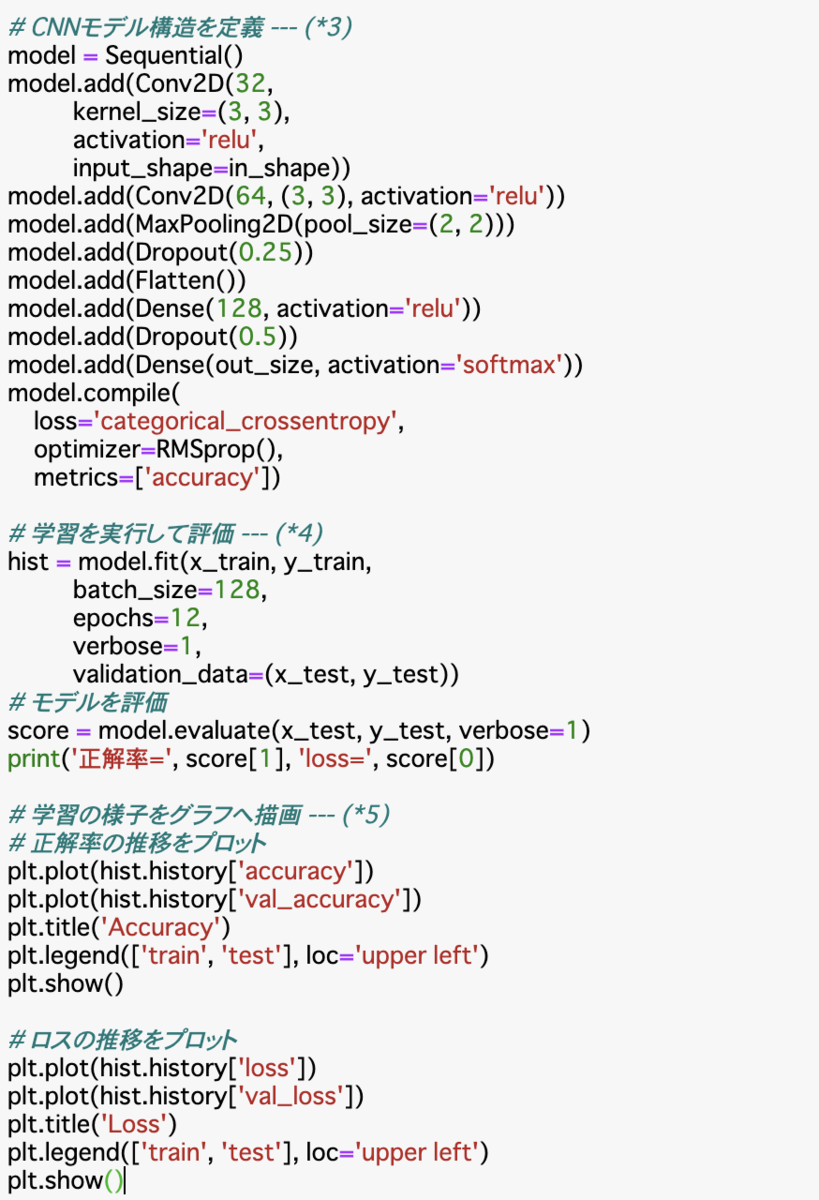
モデル構造の定義
model = Sequential()
model.add(Conv2D(32,
kernel_size=(3, 3),
activation='relu',
input_shape=in_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(out_size, activation='softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
Conv2Dは畳み込み層の作成。入力レイヤーのinput_shapeにin_shapeを指定することで三次元の入力を受け取ることができる。
流れとしては畳み込み、畳み込み、プーリング、ドロップアウト、平滑化、全結合層、ドロップアウト、出力レイヤーという流れでモデルを構築し、モデルをコンパイルしている。
学習を実行
hist = model.fit(x_train, y_train,
batch_size=128,
epochs=12,
verbose=1,
validation_data=(x_test, y_test))
batch_sizeは一度に計算するデータ量の指定。
epochsは何回繰り返し学習するか。
validation_dataで学習と同時に渡したデータのその時点での評価をhistoryオブジェクトに格納して返り値として受け取れる。
モデル評価
score = model.evaluate(x_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
学習の様子をグラフへ描画
# 正解率の推移をプロット
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# ロスの推移をプロット
plt.title('Loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
まとめ
・ETL文字データベースは日本語の手書きデータを数多く収録している。
・カタカナのように文字種類が多くても、画像データの種類が多ければ高い精度で文字認識を行うことができる。
・CNNを使うと学習に時間がかかるが判定精度は高い。