CIFAR-10の分類をCNNで判定
MLPを使った分類では0.47の正解率だったので、2回に1回以上は期待と違う答えが出ることになる。そこで畳み込みニューラルネットワークを使って、分類問題を解いてみる。
import matplotlib.pyplot as plt
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
num_classes = 10
im_rows = 32
im_cols = 32
in_shape = (im_rows, im_cols, 3)
# データを読み込む --- (*1)
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# データを正規化 --- (*2)
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
# ラベルデータをOne-Hot形式に変換
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# モデルを定義 --- (*3)
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=in_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
# モデルをコンパイル --- (*4)
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 学習を実行 --- (*5)
hist = model.fit(X_train, y_train,
batch_size=32, epochs=50,
verbose=1,
validation_data=(X_test, y_test))
# モデルを評価 --- (*6)
score = model.evaluate(X_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
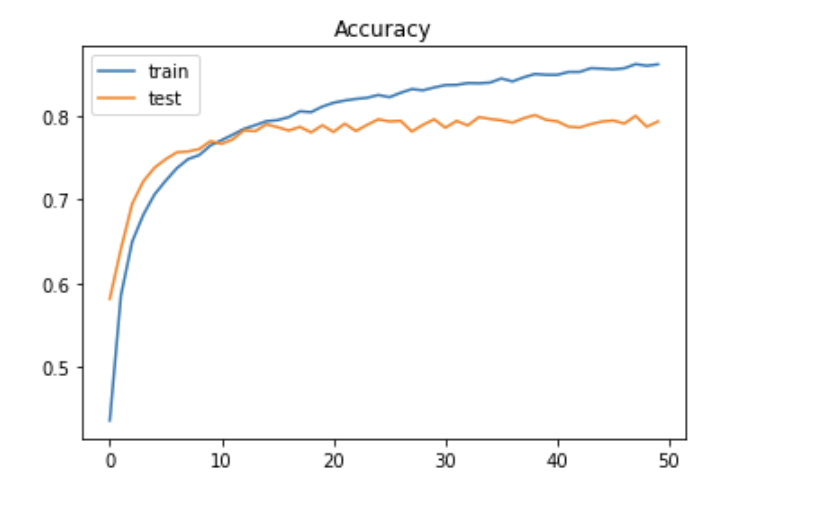
# 学習の様子をグラフへ描画 --- (*7)
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
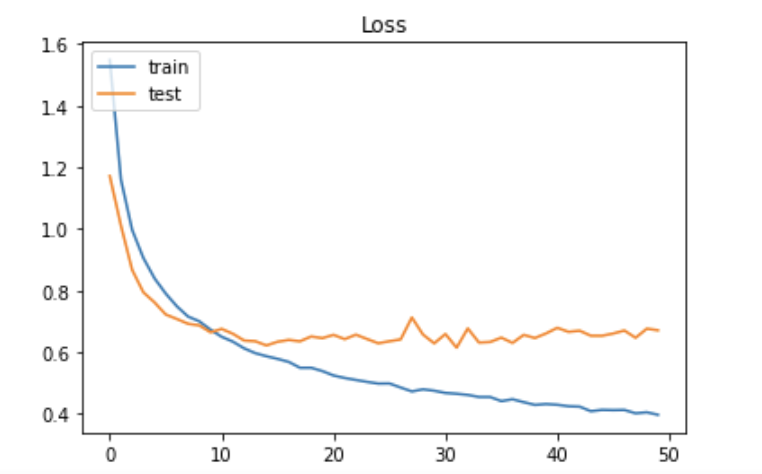
plt.title('Loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
実行結果

データの読み込みと正規化
import matplotlib.pyplot as plt
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
num_classes = 10
im_rows = 32
im_cols = 32
in_shape = (im_rows, im_cols, 3)
# データを読み込む --- (*1)
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# データを正規化 --- (*2)
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
# ラベルデータをOne-Hot形式に変換
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
cifar10.load_data()でデータ読み込み。
MLPではx_train、x_testを一次元の配列にしたが、CNNでは縦✖️横✖️RGB色空間の三次元のデータをそのまま渡すことができる。
ラベルデータをkeras.utils.to_categorical()でone-hotベクトルに変換。
モデル定義
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=in_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
CIFAR-10のデータセットは以前行った手書き数字の判定よりずっと複雑になるので、たくさんの畳み込み層とプーリング層を用意したネットワークを構築する。
このモデルでは、畳み込み、畳み込み、プーリング、ドロップアウト、畳み込み、畳み込み、プーリング、ドロップアウト、平滑化と何層にもわたる構造を記述している。これは2014年に行われた画像認識コンテスト[ILSVRC-2014]で優秀な成績を収めたVGGのチームが利用したモデルに似たものでVGG likeと呼ばれている。
model.add(Conv2D(32, (3, 3), activation='relu'))
上記は下記と同義
model.add(Conv2D(32, 3,3)))
model.add(Activation('relu'))
padding='same'はデフォルトの状態では、padding='valid'が指定されており、画像にそのままフィルターが適用されていく。28✖️28ピクセルの画像をデフォルトの状態で処理したときは26✖️26の画像に畳み込まれたがpadding='same'を指定すると画像のサイズを変えず、端の特徴もより捉えることができる。
Dropoutは過学習を抑制する方法として利用される。Dropoutは特定のレイヤーの出力を学習時にランダムで0に落とすことで、一部のデータが欠損していても正しく認識ができるようにする。これにより、画像の一部の局所特徴が過剰に評価されてしまうのを防ぎ、モデルの精度を向上させることができる。引数は0.3を指定すると前の層の出力の内30%を0にすることになる。
モデルコンパイル
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
学習実行
hist = model.fit(X_train, y_train,
batch_size=32, epochs=50,
verbose=1,
validation_data=(X_test, y_test))
モデル評価
score = model.evaluate(X_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
学習の様子をグラフに描画
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
plt.title('Loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()