TF-IDFの手法でモジュール作成
TF-IDFとは
BOW(Bag-of-Words)のように文章をベクトルデータに変換する手法のこと。BOWの手法では単語の出現頻度によって文章を数値化していた。TF-IDFでは単語の出現頻度に加えて、文章全体における単語の重要度も考慮するもの。TF-IDFは文書内の特徴的な単語を見つけることを重視する。その手法として、学習させる文章全ての文書で、その単語がどのくらいの頻度で使用されているかを調べていく。例えば、ありふれた「です」、「ます」などの単語の重要度を低くし、他の文書では見られないような希少な単語があれば、その単語を重要なものとみなして計算を行う。つまり、出現頻度を数えるだけではなくて、出現回数が多いもののレートをさげ、出現頻度の低いもののレートをあげるような形で単語をベクトル化していく。TF-IDFを使用することで、単語の出現頻度を数得るよりも、ベクトル化の精度向上が期待できる。


実行結果

4つ目のデータを見てみると0.7954...と高い数値を表しているものがある。これは日曜という単語を示しており、他の文章で使用されていない特徴的な単語なため数値が高くなっていることがわかる。
このプログラムでは文章中の単語の重要度に注目したTF-IDFを用いて、単語ごとの希少性を示したデータを出力していく。
TF-IDFを実践するにはscikit-learnの「TfrdVectorizer」も有名だが、追加で日本語への対応処理が必要なので今回は用いていない。
MeCabの初期化と辞書などの定義
import MeCab
import pickle
import numpy as np
# MeCabの初期化 ---- (*1)
# グローバル変数 --- (*2)
word_dic = {'_id': 0} # 単語辞書
dt_dic = {} # 文書全体での単語の出現回数
files = # 全文書をIDで保存
word_dicは単語辞書。単語をキーとして値にidを持つ。
dt_dicは文書全体での単語の出現回数を持つ。一つの文章に複数同じ単語が出現しても1回でカウントする。
filesは全文書をIDで保存する。一つ一つの文章をIDで表現したデータを格納する配列。
モジュールテスト
if __name__ == '__main__':
add_text('雨')
add_text('今日は、雨が降った。')
add_text('今日は暑い日だったけど雨が降った。')
add_text('今日も雨だ。でも日曜だ。')
print(calc_files())
print(word_dic)
add_text()関数
def add_text(text):
'''テキストをIDリストに変換して追加''' # --- (*5)
ids = words_to_ids(tokenize(text))
files.append(ids)
words_to_ids()関数からは渡したテキストをIDで表現した配列が返される。
それをfilesに追加。
tokenize()関数
def tokenize(text):
result =
word_s = tagger.parse(text)
for n in word_s.split("\n"):
if n == 'EOS' or n == '': continue
p = n.split("\t")[1].split(",")
h, h2, org = (p[0], p[1], p[6])
if not (h in ['名詞', '動詞', '形容詞']): continue
if h == '名詞' and h2 == '数': continue
result.append(org)
return result
if not (h in ['名詞', '動詞', '形容詞']): continueではストップワードの除去。
その下のif文でも名詞に数詞が含まれる場合はスキップしている。
result.append(org)で形態素解析した単語の原型をresultに追加していくことでストップワードを除去し、テキストの単語をIDで表現する準備をする。
words_to_ids()関数
def words_to_ids(words, auto_add = True):
'''単語一覧をIDの一覧に変換する''' # --- (*4)
result =
for w in words:
if w in word_dic:
result.append(word_dic[w])
continue
elif auto_add:
id = word_dic[w] = word_dic['_id']
word_dic['_id'] += 1
result.append(id)
return result
add_text()関数のwords_to_ids(tokenize(text))の部分でtokenize()関数の返り値を引数にしているので、テキストからストップワードを除去し、単語の原型が格納されている配列を引数にしている。
ここでは引数の単語をIDに変換していく。
word_dic(単語辞書)にループで回ってきた単語が含まれていなければ辞書に追加し、新たにその単語に割り振られたIDをresultに追加、含まれていればその単語をキーとする値(ID)を取得しresultに追加。
これによりresultにテキストをIDで表現した配列が生成される。
calc_files()関数
if __name__ == '__main__':
add_text('雨')
add_text('今日は、雨が降った。')
add_text('今日は暑い日だったけど雨が降った。')
add_text('今日も雨だ。でも日曜だ。')
print(calc_files())
print(word_dic)
次にcalc_files()関数を見ていく。
この関数は全文章で出現する単語の頻度と全文章での希少性を掛け合わせることで文章ごとの単語の重要性を示すデータを返す関数。
def calc_files():
'''追加したファイルを計算''' # --- (*7)
global dt_dic
result =
doc_count = len(files)
dt_dic = {}
# 単語の出現頻度を数える --- (*8)
for words in files:
used_word = {}
data = np.zeros(word_dic['_id'])
for id in words:
data[id] += 1
used_word[id] = 1
# 単語tが使われていればdt_dicを加算 --- (*9)
for id in used_word:
if not(id in dt_dic): dt_dic[id] = 0
dt_dic[id] += 1
# 出現回数を割合に直す --- (*10)
data = data / len(words)
result.append(data)
# TF-IDFを計算 --- (*11)
for i, doc in enumerate(result):
for id, v in enumerate(doc):
idf = np.log(doc_count / dt_dic[id]) + 1
doc[id] = min([doc[id] * idf, 1.0])
result[i] = doc
return result
global dt_dicで関数内でのdt_dicの変更がそのままグローバル変数のdt_dicに反映される。
for words in files:でテキストをIDで表現し配列がそれぞれ格納されている二次元配列をループ。
np.zeros()で単語辞書の単語数を持つ配列を作成。
for id in words:でテキストをIDで表現したデータをループするので単語のIDをidに格納して処理していく。data[id]+=1でその文章中での単語の出現頻度をカウントする配列でIDの出現頻度をカウント。
used_word[id] = 1ではその文章で出現した単語IDを格納していく。一つの文章中に複数同じ単語が出現しても値は1。
for id in used_word:で出現した単語IDを取得して処理。dt_dic(文書全体での単語の出現頻度)に含まれていなければそのIDをキーとする要素を追加。dt_dic[id]+=1で加算。
result.append(data)で出現頻度を割合に直したデータをresultに格納。
idf = np.log(doc_count / dt_dic[id]) +1で文書の数から任意の全体での単語の出現頻度を割ることで出現した回数が多いものほど小さい値になる。np.log()はネイピア数(これは定数で2.7....)を底にもつ対数を返すもの。対数にすることで大小関係は変わらず0.0
~1.0で表現できるから?対数に変換する明確な理由はわからなかった。ただ、一旦TF-IDFの手法ではこうすると覚えておこう。
doc[id]=min([doc[id]*idf, 1.0])でdic[id](単語の出現頻度を割合で表記したもの)にidf(全体における単語の希少性)を掛け合わせることで全体の文章でのその単語の希少性を示した値にdic[id]を更新する。
result[i] = docで更新したdoc(出現頻度を割合で表現しているデータ)で更新し大元の各文章での単語の出現頻度を割合で表記したデータを作り替えている。
CNNでカタカナ文字の分類
MLPでの学習結果と見比べてみる。
hanamichi-sukusuku.hatenablog.com
上記の記事でMLPの簡単なモデルでの結果を出力している。

実行結果

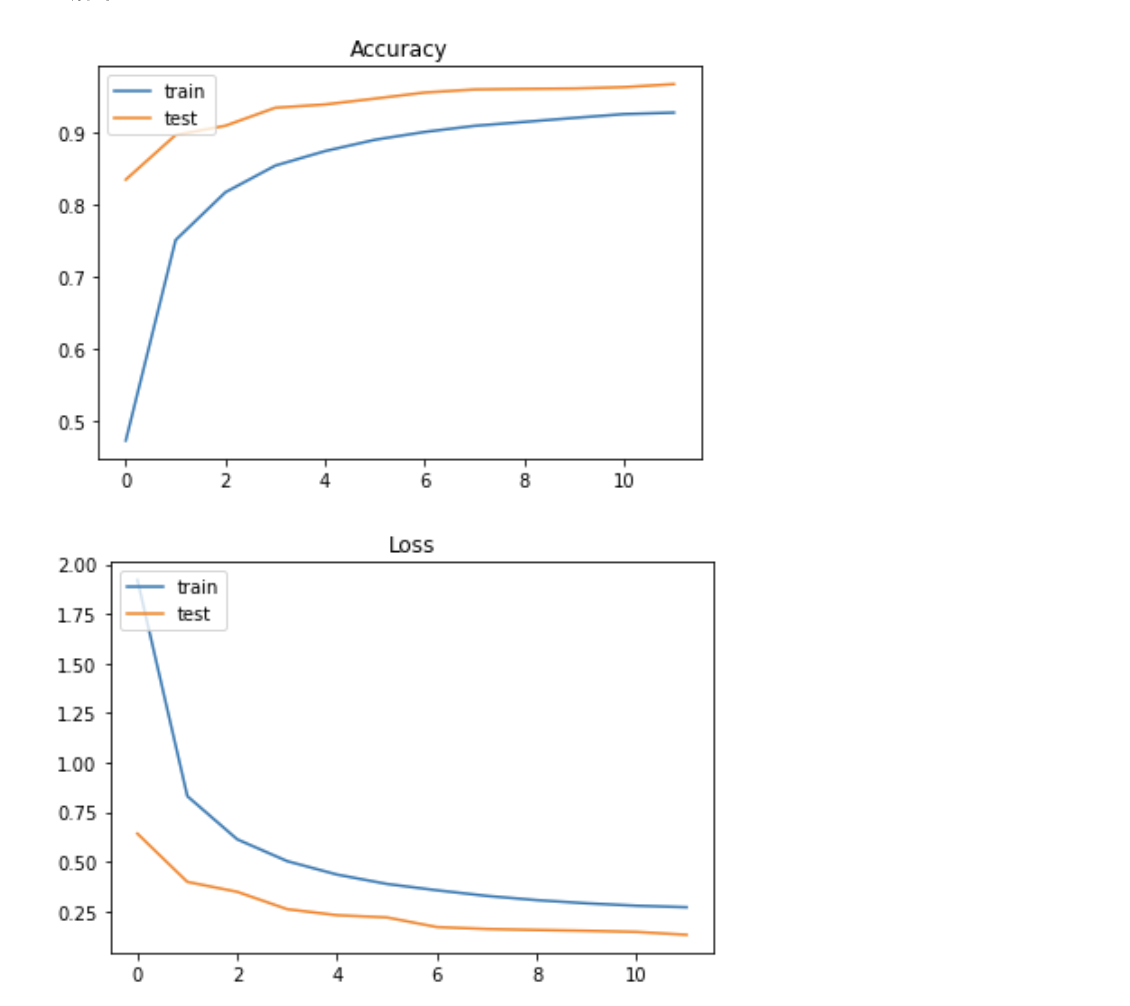
MLPでの評価結果は約90%だったのに対してCNNでの評価結果は約96%と高いものになった。
必要な値の定義と画像データの読み込み
import cv2, pickle
from sklearn.model_selection import train_test_split
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import RMSprop
from keras.datasets import mnist
import matplotlib.pyplot as plt
# データファイルと画像サイズの指定
data_file = "./png-etl1/katakana.pickle"
im_size = 25
out_size = 46 # ア-ンまでの文字の数
im_color = 1 # 画像の色空間/グレイスケール
in_shape = (im_size, im_size, im_color)
# カタカナ画像のデータセットを読み込む --- (*1)
data = pickle.load(open(data_file, "rb"))
im_sizeは今回扱う画像データは25✖️25なので25を定義しておく。
out_sizeはア~ンまでの数の46を定義。モデルの出力レイヤーのユニット数などに使用する。
im_colorはグレースケールのデータなので1を定義。RGB画像の場合は3。
in_shapeは今回のモデルには三次元の配列を扱うので1列の要素を25列持ち、それが25行の三次元配列によって一つの画像が表現されるので25(幅),25(高さ),1(色空間)の三次元の配列に変換する時に使用する。
pickle.load()で画像データ読み込み。
画像データの変形、ラベルデータone-hotベクトル化
y =
x =
for d in data:
(num, img) = d
img = img.astype('float').reshape(
im_size, im_size, im_color) / 255
y.append(keras.utils.to_categorical(num, out_size))
x.append(img)
x = np.array(x)
y = np.array(y)
読み込んだ画像データ(dataは(ラベルデータ,画像データ)このように格納されている)をreshape()で次元を変換する。既に25✖️25のまとまりでデータがループしてくるので25行,25列,1要素の三次元に変換。CNNのモデルを使うのでこの処理が必要。255で割ることで0.0~1.0で表現できるようにしている。
ラベルデータ(num)はkeras.utils.to_categorical()でone-hotベクトル化。46クラスに分類するので第二引数にout_sizeを指定。
学習用、テスト用に分割
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size = 0.2, train_size = 0.8, shuffle = True)
ここでx_train.shapeを実行してみると
(55309, 25, 25, 1)のように表示される。これは、(画像数, 画像幅, 画像高さ, 色数)の次元を持つ配列になっていることを表している。shapeでは各次元毎の要素数を確認することができる。
モデル構造の定義
model = Sequential()
model.add(Conv2D(32,
kernel_size=(3, 3),
activation='relu',
input_shape=in_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(out_size, activation='softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
Conv2Dは畳み込み層の作成。入力レイヤーのinput_shapeにin_shapeを指定することで三次元の入力を受け取ることができる。
流れとしては畳み込み、畳み込み、プーリング、ドロップアウト、平滑化、全結合層、ドロップアウト、出力レイヤーという流れでモデルを構築し、モデルをコンパイルしている。
学習を実行
hist = model.fit(x_train, y_train,
batch_size=128,
epochs=12,
verbose=1,
validation_data=(x_test, y_test))
batch_sizeは一度に計算するデータ量の指定。
epochsは何回繰り返し学習するか。
validation_dataで学習と同時に渡したデータのその時点での評価をhistoryオブジェクトに格納して返り値として受け取れる。
モデル評価
score = model.evaluate(x_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
学習の様子をグラフへ描画
# 正解率の推移をプロット
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# ロスの推移をプロット
plt.title('Loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
まとめ
・ETL文字データベースは日本語の手書きデータを数多く収録している。
・カタカナのように文字種類が多くても、画像データの種類が多ければ高い精度で文字認識を行うことができる。
・CNNを使うと学習に時間がかかるが判定精度は高い。
カタカナ画像のデータを簡単なニューラルネットワークで分類

実行結果

比較的高い結果を得ることができた。
必要な値の定義、画像データ読み込み
import numpy as np
import cv2, pickle
from sklearn.model_selection import train_test_split
import keras
# データファイルと画像サイズの指定 --- (*1)
data_file = "./png-etl1/katakana.pickle"
im_size = 25
in_size = im_size * im_size
out_size = 46 # ア-ンまでの文字の数
# 保存した画像データ一覧を読み込む --- (*2)
data = pickle.load(open(data_file, "rb"))
hanamichi-sukusuku.hatenablog.com
上記で保存したカタカナ画像データをpickle.load()で読み込む。
out_sizeはア~ンまでの文字の個数。最終的に判定したいクラス数を定義。
im_size,in_sizeは画像データのサイズが25✖️25なのでそのサイズを定義。
画像を0~1の範囲の直し、x,yのデータを作成
y =
x =
for d in data:
(num, img) = d
img = img.reshape(-1).astype('float') / 255
y.append(keras.utils.to_categorical(num, out_size))
x.append(img)
x = np.array(x)
y = np.array(y)
画像データを読み込んだdataには画像データとそれに対応したラベルデータが格納されているので、num, imgでそれぞれ分けている。imgに格納された画像データをreshape()で一次元にし、astype()でデータ型変換。255で割ることで0.0~1.0で表現するようにしている。
ラベルデータはkeras.utils.to_categorical()で46クラスで表現したラベルデータに変換しone-hotベクトルにする。
学習用とテスト用に分割
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size = 0.2, train_size = 0.8, shuffle = True)
モデル定義
Dense = keras.layers.Dense
model = keras.models.Sequential()
model.add(Dense(512, activation='relu', input_shape=(in_size,)))
model.add(Dense(out_size, activation='softmax'))
このモデルでは一次元の配列を使用するので25✖️25の値が格納されているin_sizeをinput_shape()に渡す。
出力レイヤーのout_sizeは46種類の結果が存在するのでその値の46を指定。
モデルのコンパイルと学習
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=20, epochs=50, verbose=1,
validation_data=(x_test, y_test))
モデル評価
score = model.evaluate(x_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
ETLデータベースの画像をラベルデータと画像データに分けて保存

実行結果


hanamichi-sukusuku.hatenablog.com
このプログラムでは上記でETL1のデータベースから読み込んだカタカナ手書き文字のデータをラベルデータと画像データに分けて保存していく。
保存先や画像サイズの指定
im_size = 25 # 画像サイズ
save_file = out_dir + "/katakana.pickle" # 保存先
plt.figure(figsize=(9, 17)) # 出力画像を大きくする
im_sizeで25にしているのは必要最低限のサイズに縮小してからモデルに学習させるため。
save_fileには保存先のパスを格納。
plt.figure()では画像の描画領域を指定している。引数のfigsize=(width, height)のように指定していて単位はインチ。
カタカナの画像が入っているディレクトリから画像を取得
kanadir = list(range(177, 220+1))
kanadir.append(166) # ヲ
kanadir.append(221) # ン
result = []
for i, code in enumerate(kanadir):
img_dir = out_dir + "/" + str(code)
fs = glob.glob(img_dir + "/*")
print("dir=", img_dir)
# 画像を読み込んでグレイスケールに変換しリサイズする --- (*3)
for j, f in enumerate(fs):
img = cv2.imread(f)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.resize(img_gray, (im_size, im_size))
result.append([i, img])
# Jupyter Notebookで画像を出力
if j == 3:
plt.subplot(11, 5, i + 1)
plt.axis("off")
plt.title(str(i))
plt.imshow(img, cmap='gray')
変数kanadirには166,177~221までのディレクトリにア~ンまでのカタカナのデータが入っているのでそのディレクトリ名が入ったリストを作成。
resultは最終的に保存するラベルデータと画像データのリストを定義。
fs=glob.glob(img_dir+"/*")で各ディレクトリの入ったファイル名(画像データ名)を全て取得。
fsに格納されたファイル名をfor文で回し、それぞれの画像をcv2.imread()で読み込む。
グレースケールに変換。
cv2.resize()でサイズ変換。
resultにfor文でenumerate()を使用しているのでiにkanadir(166,177~221のディレクトリ名のリスト)のインデックス番号が入っているのでそれをラベルにした画像データを追加。
plt.subplot()で複数の画像を一つのプロットに描く。
グレースケールの画像データに変換しているのでplt.imshow()でcmap='gray'を指定。
ラベルと画像データの保存
pickle.dump(result, open(save_file, "wb"))
plt.show()
print("ok")
resultにはラベル、それに対応した画像データが格納されているので、pickle.dump()でresultと保存先のファイルを開き保存。
ETL文字データベースを画像に変換

実行結果
実行するとカタカナの画像データが複数のディレクトリに保存されている。
保存先のディレクトリの作成
outdir = "png-etl1/"
if not os.path.exists(outdir): os.mkdir(outdir)
ETLデータの中身のファイル名を全て取得
files = glob.glob("ETL1/*")
ファイルごとに処理をしていく
for fname in files:
if fname == "ETL1/ETL1INFO": continue # 情報ファイルは飛ばす
print(fname)
# ETL1のデータファイルを開く --- (*2)
f = open(fname, 'rb')
f.seek(0)
while True:
# メタデータ+画像データの組を一つずつ読む --- (*3)
s = f.read(2052)
if not s: break
# バイナリデータなのでPythonが理解できるように抽出 --- (*4)
r = struct.unpack('>H2sH6BI4H4B4x2016s4x', s)
code_ascii = r[1]
code_jis = r[3]
# 画像データとして取り出す --- (*5)
iF = Image.frombytes('F', (64, 63), r[18], 'bit', 4)
iP = iF.convert('L')
# 画像を鮮明にして保存
dir = outdir + "/" + str(code_jis)
if not os.path.exists(dir): os.mkdir(dir)
fullpath = dir + "/" + fn
#if os.path.exists(fullpath): continue
enhancer = ImageEnhance.Brightness(iP)
f=open(fname, 'rb')でファイルを開く。
f.seek(0)では読み込む位置を指定している。
例えば
(text.txt)
text
note
book
pen
上記のようなtext.txtというテキストファイルがあった時に必ず先頭から読み込まれるとは限らない。そこで現在の位置を知るためには
with open('text.txt', 'r') as t:
print(t.tell())
print(t.read(4))
>>0
>>text
tell()で現在の位置を知ることができる。この場合でいうとtextのtの位置にいることがわかる。そして、read()で引数に4を指定しているが現在の位置から4番目のものを読み込むことでtextと表示されている。
seek()ではこの位置を変更することができる。
例えば
with open('text.txt', 'r') as t:
t.seek(5)
print(t.tell())
print(t.read(4))
>> 5
>>note
改行文字が入るので5番目がnoteのnの部分になる。seek(5)とすることで5番目の部分に位置を移動することができた。
f.seek(0)では先頭から読み込むように位置を指定している。
s = f.read(2052)この部分では今回扱うデータは2052バイトの固定長になっているため先頭から2052番目までを読み込んでいる。
この直後にprint(f.tell())を記述すると

それぞれ位置が移動し読み込んでいるのがわかる。
バイナリーデータなのでpythonが理解できるように抽出
r = struct.unpack('>H2sH6BI4H4B4x2016s4x', s)
structモジュールはバイナリーデータを処理するときのもの。structモジュールを使うことで細かくフォーマットを指定してバイナリーデータを作成したり、バイナリデータから数値に変換したりすることに利用することができる。
主な使い方はパックとアンパックがあり、パックは数値型などの値をフォーマットを指定してbytes型に変換すること、
pack(フォーマット, 値)
アンパックはbytes型のバイナリーデータを元の型の値に戻すこと。
unpack(フォーマット, バイナリーデータ)
今回はバイナリーデータをpython理解できるようにしたいのでアンパックを使用する。
>はビックエンディアンと言ってバイトがバイナリデータが最上位ビットから並べられている時に使用。例えば、\x00\x01では、\x00が上位バイトで\x01が下位バイトとなる。
unpackのフォーマットで指定するバイト数をバイナリーデータのバイト数が同じ出ないとエラーになる。
2sとか6Bとか指定するフォーマット文字の前に数値を与えるとその値✖️フォーマット文字になる。2sならss、6BならBBBBBB。2016sは2016回sを指定することになる。今回の場合合計すると2052バイトになる。
それぞれのフォーマット文字列が何を示すのかはドキュメントなどを見ればわかったがread()した中身をみてもなぜそのフォーマット文字をしてするのかわからなかった。
とりあえずこの処理でpythonが理解できるような意味のある単位ごとに抽出する。
画像データとして取り出す
iF = Image.frombytes('F', (64, 63), r[18], 'bit', 4)
画像処理ライブラリであるpillowから画像を処理するimageモジュールのfrombytes()関数を利用してバイト列から画像を生成していく。
PIL.Image.frombytes(mode, size, data, decoder_name='raw', *args)
mode(第一引数)には生成する画像のモードを指定する。データのモードとこのモードは合わせる必要がある。
size(第二引数)には生成する画像のサイズを指定する。(width, height)のフォーマットをタプルで渡す。
data(第三引数)にはモードに指定されたバイト列(データ)を渡す。
decoder_name='raw(第四引数)ここにはデコーダーの名前を指定。デフォルトはraw。
args(第五引数)ここにはデコーダーの引数を指定。
返り値はImageオブジェクト。
浮動少数点の構造、符号、仮数、指数で表せれる。

同じようにこの「符号」、「仮数」、「指数」ビットで表現します。浮動小数点では 32 ビットを以下のように 3 つに分割。

32ビットの浮動小数を表すのはこの形。
今回の第三引数に指定したデータは32ビットの浮動小数で表されているため第一引数にはそのモードを指す"F"が入る。
第三引数のr[18]はstruct.unpack()で格納した変数rの中身を見るとインデックスで18番目から画像を表すデータになっている。
iP = iF.convert('L')
ここではImageオブジェクトが格納されたiFにconvert("L")を指定することでグレースケールに変換している。
ここでは画像ファイル名を作成しており、format()メソッドを使用する。
format()メソッドは引数に指定したものを文章に置き換えることができる。
"{0}さんは{1}cmです".format("山田", 180)
>>山田さんは180cmです
このように引数のインデックス番号に対応して値が格納される。
書式を指定したい場合は
{インデックス番号: 書式設定} この形で指定する。
今回だと:の左側がインデックス、右が書式設定なので02xや04xが書式設定。
0はゼロを先頭に追加するオプションで、xは16進数で表すことを指定している。xの前の2や4は表示する桁数を指定。文字列なら左詰め、数値なら右詰めで桁をピックアップする。
fullpath = dir + "/" + fn
ファイル名ができたのでパスを作成。
enhancer = ImageEnhance.Brightness(iP)
ImageEnhanceモジュールで画像の明るさを変える。返り値はenhanceオブジェクト。
ImageEnhanceモジュールで作成したenhanceオブジェクトにenhance()メソッドを適用する。引数には1.0が元画像と同じ明度で大きくなるにつれて明るく、小さくなるにつれて暗くなる。
save()メソッドで保存先のパスと拡張子を指定して保存。
CNNを利用して作成した重みデータを保存し、そのデータで画像の判定
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
import matplotlib.pyplot as plt
im_size = 32 * 32 *3
num_classes = 10
im_rows = 32
im_cols = 32
in_shape = (im_rows, im_cols, 3)
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=in_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
# モデルをコンパイル --- (*4)
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.load_weights('cifar10-weight.h5')
import cv2
import numpy as np
labels = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
im = cv2.imread('test-car.jpg')
im=cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = cv2.resize(im, (32, 32))
plt.imshow(im)
plt.show()
im = im.astype('float32') / 255
r = model.predict(np.array([im]), batch_size=32, verbose=1)
res = r[0]
for i, acc in enumerate(res):
print(labels[i], "=", int(acc * 100))
print("-----")
print("予測した結果=", labels[res.argmax()])
実行結果

hanamichi-sukusuku.hatenablog.com
今回使用する重みデータは上記で作成したもの。
モデルにパラメーターを渡してからが重要なのでここでのモデル構築に関しては割愛する。
model.load_weights('cifar10-weight.h5')
import cv2
import numpy as np
labels = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
im = cv2.imread('test-car.jpg')
im=cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = cv2.resize(im, (32, 32))
plt.imshow(im)
plt.show()
im = im.astype('float32') / 255
r = model.predict(np.array([im]), batch_size=32, verbose=1)
res = r[0]
for i, acc in enumerate(res):
print(labels[i], "=", int(acc * 100))
print("-----")
print("予測した結果=", labels[res.argmax()])
この部分のプログラムをみていく。
重みデータ読み込み
model.load_weights()で保存してある重みデータのファイル名を指定し読み込む。
画像の読み込みと表示
画像の読み込みにopencvを利用。
imread()で画像を読み込み、cvtColor()でRGB色空間に変換、今回のモデルでは32✖️32ピクセルの画像を処理できるようになっているのでresize()で32✖️32の画像に変換。
画像データの正規化
im = im.astype('float32') / 255で0.0~1.0で表現するように変換する。今回はCNNでの判定なので三次元のデータのまま使用できる。もし、MLPのアルゴリズムを使用するならここで一次元の配列にする必要がある。
結果の予測
model.predict()で画像データを予測。
変数rには最終的なクラス数である10個の配列になっている。

出力すると上記のような中身になっている。
それぞれのラベルの予測結果を表示
res = r[0]
for i, acc in enumerate(res):
print(labels[i], "=", int(acc * 100))
予測結果は二次元の配列になっているのでres = r[0]
enumerate()を使用するとインデックス番号と要素をそれぞれ取得できる。
返り値は(インデックス番号, 要素)。つまりfor文のiにインデックス、accに要素が入る。
ラベルごとに100をかけた値を出力。
実行結果でほとんどが0なのはint()を使用した時に端数は切り捨てられるから。
予測結果の中身をみると5.5786779e-14など見慣れないものがあるがこれは
5.5786779✖️0.00000000000001のことで計算を行うと1.0未満になるためint()で処理すると0になる。
2.34e+4なら2.34✖️10000、2.34e-4なら2.34✖️0.0001を意味する。
配列から最大値を取得し、そのラベルを出力
print("予測した結果=", labels[res.argmax()])
argmax()で配列から最大の値を持つインデックス番号を取得。
labelsの中からそれに対応した値を取得し出力すると予測結果のラベルがわかる。
CIFAR-10の分類をCNNで判定
MLPを使った分類では0.47の正解率だったので、2回に1回以上は期待と違う答えが出ることになる。そこで畳み込みニューラルネットワークを使って、分類問題を解いてみる。
import matplotlib.pyplot as plt
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
num_classes = 10
im_rows = 32
im_cols = 32
in_shape = (im_rows, im_cols, 3)
# データを読み込む --- (*1)
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# データを正規化 --- (*2)
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
# ラベルデータをOne-Hot形式に変換
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# モデルを定義 --- (*3)
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=in_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
# モデルをコンパイル --- (*4)
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 学習を実行 --- (*5)
hist = model.fit(X_train, y_train,
batch_size=32, epochs=50,
verbose=1,
validation_data=(X_test, y_test))
# モデルを評価 --- (*6)
score = model.evaluate(X_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
# 学習の様子をグラフへ描画 --- (*7)
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
plt.title('Loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
実行結果

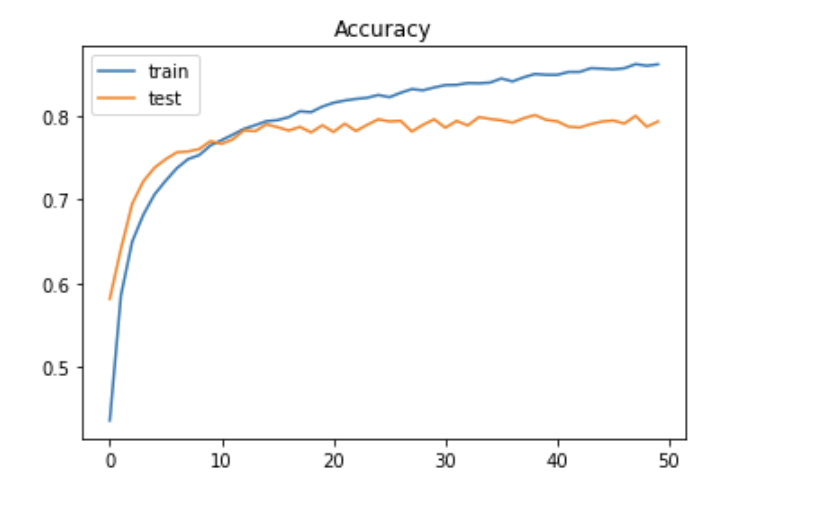
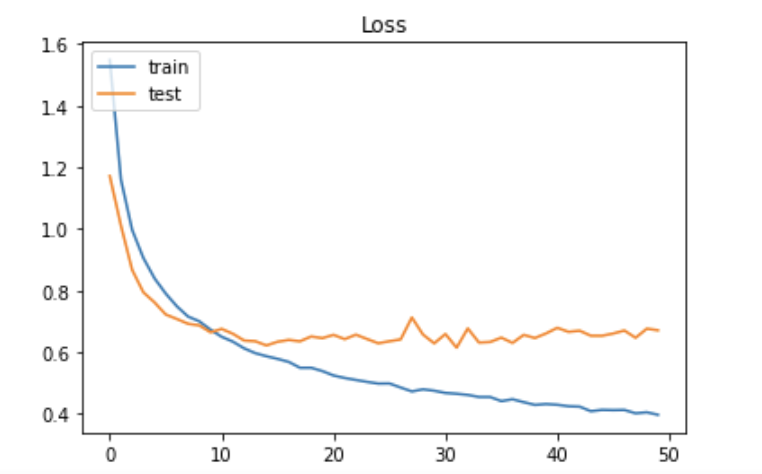
データの読み込みと正規化
import matplotlib.pyplot as plt
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
num_classes = 10
im_rows = 32
im_cols = 32
in_shape = (im_rows, im_cols, 3)
# データを読み込む --- (*1)
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# データを正規化 --- (*2)
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
# ラベルデータをOne-Hot形式に変換
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
cifar10.load_data()でデータ読み込み。
MLPではx_train、x_testを一次元の配列にしたが、CNNでは縦✖️横✖️RGB色空間の三次元のデータをそのまま渡すことができる。
ラベルデータをkeras.utils.to_categorical()でone-hotベクトルに変換。
モデル定義
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=in_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
CIFAR-10のデータセットは以前行った手書き数字の判定よりずっと複雑になるので、たくさんの畳み込み層とプーリング層を用意したネットワークを構築する。
このモデルでは、畳み込み、畳み込み、プーリング、ドロップアウト、畳み込み、畳み込み、プーリング、ドロップアウト、平滑化と何層にもわたる構造を記述している。これは2014年に行われた画像認識コンテスト[ILSVRC-2014]で優秀な成績を収めたVGGのチームが利用したモデルに似たものでVGG likeと呼ばれている。
model.add(Conv2D(32, (3, 3), activation='relu'))
上記は下記と同義
model.add(Conv2D(32, 3,3)))
model.add(Activation('relu'))
padding='same'はデフォルトの状態では、padding='valid'が指定されており、画像にそのままフィルターが適用されていく。28✖️28ピクセルの画像をデフォルトの状態で処理したときは26✖️26の画像に畳み込まれたがpadding='same'を指定すると画像のサイズを変えず、端の特徴もより捉えることができる。
Dropoutは過学習を抑制する方法として利用される。Dropoutは特定のレイヤーの出力を学習時にランダムで0に落とすことで、一部のデータが欠損していても正しく認識ができるようにする。これにより、画像の一部の局所特徴が過剰に評価されてしまうのを防ぎ、モデルの精度を向上させることができる。引数は0.3を指定すると前の層の出力の内30%を0にすることになる。
モデルコンパイル
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
学習実行
hist = model.fit(X_train, y_train,
batch_size=32, epochs=50,
verbose=1,
validation_data=(X_test, y_test))
モデル評価
score = model.evaluate(X_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
学習の様子をグラフに描画
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
plt.title('Loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()