カタカナ画像のデータを簡単なニューラルネットワークで分類

実行結果

比較的高い結果を得ることができた。
必要な値の定義、画像データ読み込み
import numpy as np
import cv2, pickle
from sklearn.model_selection import train_test_split
import keras
# データファイルと画像サイズの指定 --- (*1)
data_file = "./png-etl1/katakana.pickle"
im_size = 25
in_size = im_size * im_size
out_size = 46 # ア-ンまでの文字の数
# 保存した画像データ一覧を読み込む --- (*2)
data = pickle.load(open(data_file, "rb"))
hanamichi-sukusuku.hatenablog.com
上記で保存したカタカナ画像データをpickle.load()で読み込む。
out_sizeはア~ンまでの文字の個数。最終的に判定したいクラス数を定義。
im_size,in_sizeは画像データのサイズが25✖️25なのでそのサイズを定義。
画像を0~1の範囲の直し、x,yのデータを作成
y =
x =
for d in data:
(num, img) = d
img = img.reshape(-1).astype('float') / 255
y.append(keras.utils.to_categorical(num, out_size))
x.append(img)
x = np.array(x)
y = np.array(y)
画像データを読み込んだdataには画像データとそれに対応したラベルデータが格納されているので、num, imgでそれぞれ分けている。imgに格納された画像データをreshape()で一次元にし、astype()でデータ型変換。255で割ることで0.0~1.0で表現するようにしている。
ラベルデータはkeras.utils.to_categorical()で46クラスで表現したラベルデータに変換しone-hotベクトルにする。
学習用とテスト用に分割
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size = 0.2, train_size = 0.8, shuffle = True)
モデル定義
Dense = keras.layers.Dense
model = keras.models.Sequential()
model.add(Dense(512, activation='relu', input_shape=(in_size,)))
model.add(Dense(out_size, activation='softmax'))
このモデルでは一次元の配列を使用するので25✖️25の値が格納されているin_sizeをinput_shape()に渡す。
出力レイヤーのout_sizeは46種類の結果が存在するのでその値の46を指定。
モデルのコンパイルと学習
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=20, epochs=50, verbose=1,
validation_data=(x_test, y_test))
モデル評価
score = model.evaluate(x_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
ETLデータベースの画像をラベルデータと画像データに分けて保存

実行結果


hanamichi-sukusuku.hatenablog.com
このプログラムでは上記でETL1のデータベースから読み込んだカタカナ手書き文字のデータをラベルデータと画像データに分けて保存していく。
保存先や画像サイズの指定
im_size = 25 # 画像サイズ
save_file = out_dir + "/katakana.pickle" # 保存先
plt.figure(figsize=(9, 17)) # 出力画像を大きくする
im_sizeで25にしているのは必要最低限のサイズに縮小してからモデルに学習させるため。
save_fileには保存先のパスを格納。
plt.figure()では画像の描画領域を指定している。引数のfigsize=(width, height)のように指定していて単位はインチ。
カタカナの画像が入っているディレクトリから画像を取得
kanadir = list(range(177, 220+1))
kanadir.append(166) # ヲ
kanadir.append(221) # ン
result = []
for i, code in enumerate(kanadir):
img_dir = out_dir + "/" + str(code)
fs = glob.glob(img_dir + "/*")
print("dir=", img_dir)
# 画像を読み込んでグレイスケールに変換しリサイズする --- (*3)
for j, f in enumerate(fs):
img = cv2.imread(f)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.resize(img_gray, (im_size, im_size))
result.append([i, img])
# Jupyter Notebookで画像を出力
if j == 3:
plt.subplot(11, 5, i + 1)
plt.axis("off")
plt.title(str(i))
plt.imshow(img, cmap='gray')
変数kanadirには166,177~221までのディレクトリにア~ンまでのカタカナのデータが入っているのでそのディレクトリ名が入ったリストを作成。
resultは最終的に保存するラベルデータと画像データのリストを定義。
fs=glob.glob(img_dir+"/*")で各ディレクトリの入ったファイル名(画像データ名)を全て取得。
fsに格納されたファイル名をfor文で回し、それぞれの画像をcv2.imread()で読み込む。
グレースケールに変換。
cv2.resize()でサイズ変換。
resultにfor文でenumerate()を使用しているのでiにkanadir(166,177~221のディレクトリ名のリスト)のインデックス番号が入っているのでそれをラベルにした画像データを追加。
plt.subplot()で複数の画像を一つのプロットに描く。
グレースケールの画像データに変換しているのでplt.imshow()でcmap='gray'を指定。
ラベルと画像データの保存
pickle.dump(result, open(save_file, "wb"))
plt.show()
print("ok")
resultにはラベル、それに対応した画像データが格納されているので、pickle.dump()でresultと保存先のファイルを開き保存。
ETL文字データベースを画像に変換

実行結果
実行するとカタカナの画像データが複数のディレクトリに保存されている。
保存先のディレクトリの作成
outdir = "png-etl1/"
if not os.path.exists(outdir): os.mkdir(outdir)
ETLデータの中身のファイル名を全て取得
files = glob.glob("ETL1/*")
ファイルごとに処理をしていく
for fname in files:
if fname == "ETL1/ETL1INFO": continue # 情報ファイルは飛ばす
print(fname)
# ETL1のデータファイルを開く --- (*2)
f = open(fname, 'rb')
f.seek(0)
while True:
# メタデータ+画像データの組を一つずつ読む --- (*3)
s = f.read(2052)
if not s: break
# バイナリデータなのでPythonが理解できるように抽出 --- (*4)
r = struct.unpack('>H2sH6BI4H4B4x2016s4x', s)
code_ascii = r[1]
code_jis = r[3]
# 画像データとして取り出す --- (*5)
iF = Image.frombytes('F', (64, 63), r[18], 'bit', 4)
iP = iF.convert('L')
# 画像を鮮明にして保存
dir = outdir + "/" + str(code_jis)
if not os.path.exists(dir): os.mkdir(dir)
fullpath = dir + "/" + fn
#if os.path.exists(fullpath): continue
enhancer = ImageEnhance.Brightness(iP)
f=open(fname, 'rb')でファイルを開く。
f.seek(0)では読み込む位置を指定している。
例えば
(text.txt)
text
note
book
pen
上記のようなtext.txtというテキストファイルがあった時に必ず先頭から読み込まれるとは限らない。そこで現在の位置を知るためには
with open('text.txt', 'r') as t:
print(t.tell())
print(t.read(4))
>>0
>>text
tell()で現在の位置を知ることができる。この場合でいうとtextのtの位置にいることがわかる。そして、read()で引数に4を指定しているが現在の位置から4番目のものを読み込むことでtextと表示されている。
seek()ではこの位置を変更することができる。
例えば
with open('text.txt', 'r') as t:
t.seek(5)
print(t.tell())
print(t.read(4))
>> 5
>>note
改行文字が入るので5番目がnoteのnの部分になる。seek(5)とすることで5番目の部分に位置を移動することができた。
f.seek(0)では先頭から読み込むように位置を指定している。
s = f.read(2052)この部分では今回扱うデータは2052バイトの固定長になっているため先頭から2052番目までを読み込んでいる。
この直後にprint(f.tell())を記述すると

それぞれ位置が移動し読み込んでいるのがわかる。
バイナリーデータなのでpythonが理解できるように抽出
r = struct.unpack('>H2sH6BI4H4B4x2016s4x', s)
structモジュールはバイナリーデータを処理するときのもの。structモジュールを使うことで細かくフォーマットを指定してバイナリーデータを作成したり、バイナリデータから数値に変換したりすることに利用することができる。
主な使い方はパックとアンパックがあり、パックは数値型などの値をフォーマットを指定してbytes型に変換すること、
pack(フォーマット, 値)
アンパックはbytes型のバイナリーデータを元の型の値に戻すこと。
unpack(フォーマット, バイナリーデータ)
今回はバイナリーデータをpython理解できるようにしたいのでアンパックを使用する。
>はビックエンディアンと言ってバイトがバイナリデータが最上位ビットから並べられている時に使用。例えば、\x00\x01では、\x00が上位バイトで\x01が下位バイトとなる。
unpackのフォーマットで指定するバイト数をバイナリーデータのバイト数が同じ出ないとエラーになる。
2sとか6Bとか指定するフォーマット文字の前に数値を与えるとその値✖️フォーマット文字になる。2sならss、6BならBBBBBB。2016sは2016回sを指定することになる。今回の場合合計すると2052バイトになる。
それぞれのフォーマット文字列が何を示すのかはドキュメントなどを見ればわかったがread()した中身をみてもなぜそのフォーマット文字をしてするのかわからなかった。
とりあえずこの処理でpythonが理解できるような意味のある単位ごとに抽出する。
画像データとして取り出す
iF = Image.frombytes('F', (64, 63), r[18], 'bit', 4)
画像処理ライブラリであるpillowから画像を処理するimageモジュールのfrombytes()関数を利用してバイト列から画像を生成していく。
PIL.Image.frombytes(mode, size, data, decoder_name='raw', *args)
mode(第一引数)には生成する画像のモードを指定する。データのモードとこのモードは合わせる必要がある。
size(第二引数)には生成する画像のサイズを指定する。(width, height)のフォーマットをタプルで渡す。
data(第三引数)にはモードに指定されたバイト列(データ)を渡す。
decoder_name='raw(第四引数)ここにはデコーダーの名前を指定。デフォルトはraw。
args(第五引数)ここにはデコーダーの引数を指定。
返り値はImageオブジェクト。
浮動少数点の構造、符号、仮数、指数で表せれる。

同じようにこの「符号」、「仮数」、「指数」ビットで表現します。浮動小数点では 32 ビットを以下のように 3 つに分割。

32ビットの浮動小数を表すのはこの形。
今回の第三引数に指定したデータは32ビットの浮動小数で表されているため第一引数にはそのモードを指す"F"が入る。
第三引数のr[18]はstruct.unpack()で格納した変数rの中身を見るとインデックスで18番目から画像を表すデータになっている。
iP = iF.convert('L')
ここではImageオブジェクトが格納されたiFにconvert("L")を指定することでグレースケールに変換している。
ここでは画像ファイル名を作成しており、format()メソッドを使用する。
format()メソッドは引数に指定したものを文章に置き換えることができる。
"{0}さんは{1}cmです".format("山田", 180)
>>山田さんは180cmです
このように引数のインデックス番号に対応して値が格納される。
書式を指定したい場合は
{インデックス番号: 書式設定} この形で指定する。
今回だと:の左側がインデックス、右が書式設定なので02xや04xが書式設定。
0はゼロを先頭に追加するオプションで、xは16進数で表すことを指定している。xの前の2や4は表示する桁数を指定。文字列なら左詰め、数値なら右詰めで桁をピックアップする。
fullpath = dir + "/" + fn
ファイル名ができたのでパスを作成。
enhancer = ImageEnhance.Brightness(iP)
ImageEnhanceモジュールで画像の明るさを変える。返り値はenhanceオブジェクト。
ImageEnhanceモジュールで作成したenhanceオブジェクトにenhance()メソッドを適用する。引数には1.0が元画像と同じ明度で大きくなるにつれて明るく、小さくなるにつれて暗くなる。
save()メソッドで保存先のパスと拡張子を指定して保存。
CNNを利用して作成した重みデータを保存し、そのデータで画像の判定
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
import matplotlib.pyplot as plt
im_size = 32 * 32 *3
num_classes = 10
im_rows = 32
im_cols = 32
in_shape = (im_rows, im_cols, 3)
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=in_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
# モデルをコンパイル --- (*4)
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.load_weights('cifar10-weight.h5')
import cv2
import numpy as np
labels = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
im = cv2.imread('test-car.jpg')
im=cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = cv2.resize(im, (32, 32))
plt.imshow(im)
plt.show()
im = im.astype('float32') / 255
r = model.predict(np.array([im]), batch_size=32, verbose=1)
res = r[0]
for i, acc in enumerate(res):
print(labels[i], "=", int(acc * 100))
print("-----")
print("予測した結果=", labels[res.argmax()])
実行結果

hanamichi-sukusuku.hatenablog.com
今回使用する重みデータは上記で作成したもの。
モデルにパラメーターを渡してからが重要なのでここでのモデル構築に関しては割愛する。
model.load_weights('cifar10-weight.h5')
import cv2
import numpy as np
labels = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
im = cv2.imread('test-car.jpg')
im=cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = cv2.resize(im, (32, 32))
plt.imshow(im)
plt.show()
im = im.astype('float32') / 255
r = model.predict(np.array([im]), batch_size=32, verbose=1)
res = r[0]
for i, acc in enumerate(res):
print(labels[i], "=", int(acc * 100))
print("-----")
print("予測した結果=", labels[res.argmax()])
この部分のプログラムをみていく。
重みデータ読み込み
model.load_weights()で保存してある重みデータのファイル名を指定し読み込む。
画像の読み込みと表示
画像の読み込みにopencvを利用。
imread()で画像を読み込み、cvtColor()でRGB色空間に変換、今回のモデルでは32✖️32ピクセルの画像を処理できるようになっているのでresize()で32✖️32の画像に変換。
画像データの正規化
im = im.astype('float32') / 255で0.0~1.0で表現するように変換する。今回はCNNでの判定なので三次元のデータのまま使用できる。もし、MLPのアルゴリズムを使用するならここで一次元の配列にする必要がある。
結果の予測
model.predict()で画像データを予測。
変数rには最終的なクラス数である10個の配列になっている。

出力すると上記のような中身になっている。
それぞれのラベルの予測結果を表示
res = r[0]
for i, acc in enumerate(res):
print(labels[i], "=", int(acc * 100))
予測結果は二次元の配列になっているのでres = r[0]
enumerate()を使用するとインデックス番号と要素をそれぞれ取得できる。
返り値は(インデックス番号, 要素)。つまりfor文のiにインデックス、accに要素が入る。
ラベルごとに100をかけた値を出力。
実行結果でほとんどが0なのはint()を使用した時に端数は切り捨てられるから。
予測結果の中身をみると5.5786779e-14など見慣れないものがあるがこれは
5.5786779✖️0.00000000000001のことで計算を行うと1.0未満になるためint()で処理すると0になる。
2.34e+4なら2.34✖️10000、2.34e-4なら2.34✖️0.0001を意味する。
配列から最大値を取得し、そのラベルを出力
print("予測した結果=", labels[res.argmax()])
argmax()で配列から最大の値を持つインデックス番号を取得。
labelsの中からそれに対応した値を取得し出力すると予測結果のラベルがわかる。
CIFAR-10の分類をCNNで判定
MLPを使った分類では0.47の正解率だったので、2回に1回以上は期待と違う答えが出ることになる。そこで畳み込みニューラルネットワークを使って、分類問題を解いてみる。
import matplotlib.pyplot as plt
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
num_classes = 10
im_rows = 32
im_cols = 32
in_shape = (im_rows, im_cols, 3)
# データを読み込む --- (*1)
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# データを正規化 --- (*2)
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
# ラベルデータをOne-Hot形式に変換
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# モデルを定義 --- (*3)
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=in_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
# モデルをコンパイル --- (*4)
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 学習を実行 --- (*5)
hist = model.fit(X_train, y_train,
batch_size=32, epochs=50,
verbose=1,
validation_data=(X_test, y_test))
# モデルを評価 --- (*6)
score = model.evaluate(X_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
# 学習の様子をグラフへ描画 --- (*7)
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
plt.title('Loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
実行結果

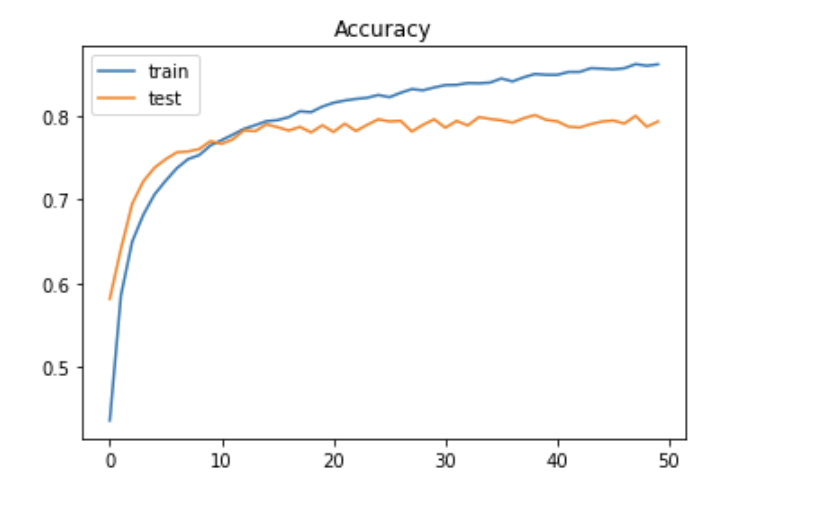
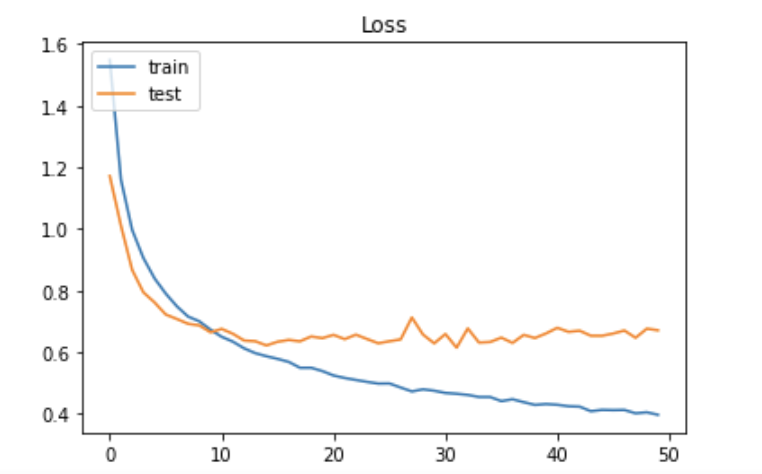
データの読み込みと正規化
import matplotlib.pyplot as plt
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
num_classes = 10
im_rows = 32
im_cols = 32
in_shape = (im_rows, im_cols, 3)
# データを読み込む --- (*1)
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# データを正規化 --- (*2)
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
# ラベルデータをOne-Hot形式に変換
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
cifar10.load_data()でデータ読み込み。
MLPではx_train、x_testを一次元の配列にしたが、CNNでは縦✖️横✖️RGB色空間の三次元のデータをそのまま渡すことができる。
ラベルデータをkeras.utils.to_categorical()でone-hotベクトルに変換。
モデル定義
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=in_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
CIFAR-10のデータセットは以前行った手書き数字の判定よりずっと複雑になるので、たくさんの畳み込み層とプーリング層を用意したネットワークを構築する。
このモデルでは、畳み込み、畳み込み、プーリング、ドロップアウト、畳み込み、畳み込み、プーリング、ドロップアウト、平滑化と何層にもわたる構造を記述している。これは2014年に行われた画像認識コンテスト[ILSVRC-2014]で優秀な成績を収めたVGGのチームが利用したモデルに似たものでVGG likeと呼ばれている。
model.add(Conv2D(32, (3, 3), activation='relu'))
上記は下記と同義
model.add(Conv2D(32, 3,3)))
model.add(Activation('relu'))
padding='same'はデフォルトの状態では、padding='valid'が指定されており、画像にそのままフィルターが適用されていく。28✖️28ピクセルの画像をデフォルトの状態で処理したときは26✖️26の画像に畳み込まれたがpadding='same'を指定すると画像のサイズを変えず、端の特徴もより捉えることができる。
Dropoutは過学習を抑制する方法として利用される。Dropoutは特定のレイヤーの出力を学習時にランダムで0に落とすことで、一部のデータが欠損していても正しく認識ができるようにする。これにより、画像の一部の局所特徴が過剰に評価されてしまうのを防ぎ、モデルの精度を向上させることができる。引数は0.3を指定すると前の層の出力の内30%を0にすることになる。
モデルコンパイル
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
学習実行
hist = model.fit(X_train, y_train,
batch_size=32, epochs=50,
verbose=1,
validation_data=(X_test, y_test))
モデル評価
score = model.evaluate(X_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
学習の様子をグラフに描画
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
plt.title('Loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
MLPでCIFAR-10のデータを分類
CIFAR-10はkerasでダウンロードできるデータセットで、飛行機や車、鳥、猫などの10カテゴリーの写真6万枚が入っている。約8000万枚の画像が「80 Million Tiny images」というWEBサイトで公開されているが、そこから6万枚の画像を抽出し、ラベル付けしたデータセットがCIFAR-10。画像はフルカラーで32✖️32ピクセルと小さな画像になっている。

実行結果

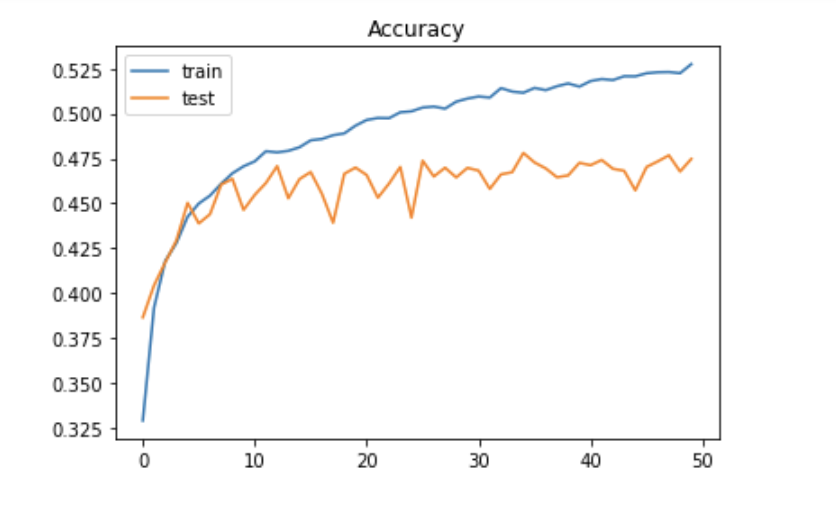
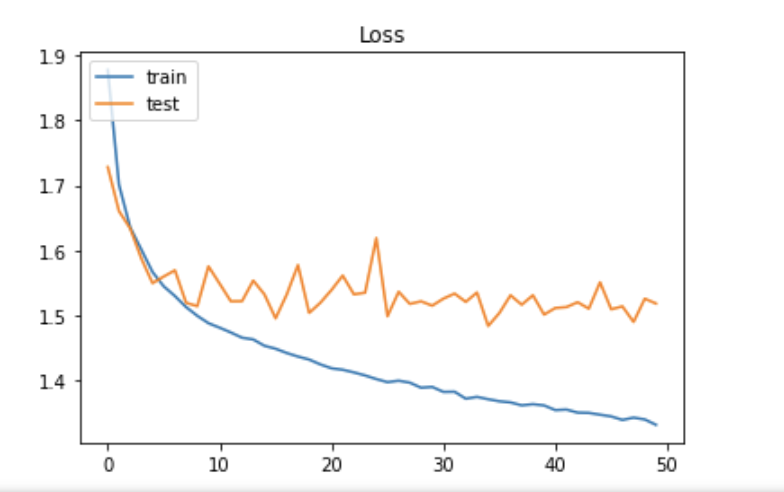
今回のプログラムではCIFAR-10のデータをMLP(多層パーセプトロン)のアルゴリズムで、分類していく。
この実行結果ではあまり正解率は良くないがどんな画像データでも、一次元の配列データに変換すれば、MLPのモデルを利用してディープラーニングが実践できることを表している。
データの読み込みと各データの処理
import matplotlib.pyplot as plt
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Dropout
num_classes = 10
im_rows = 32
im_cols = 32
im_size = im_rows * im_cols * 3
# データを読み込む --- (*1)
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# データを一次元配列に変換 --- (*2)
X_train = X_train.reshape(-1, im_size).astype('float32') / 255
X_test = X_test.reshape(-1, im_size).astype('float32') / 255
# ラベルデータをOne-Hot形式に変換
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
CIFAR-10をダウンロードするためcifar10.load_data()で各変数に格納している。そして、画像データをreshape()で一次元に変換。ラベルデータをone-hotベクトルに変換。
im_size = im_rows * im_cols *3の部分は一つの画像を一次元にしたとき、区切られる要素数の値をim_sizeに格納している。今回の画像は一枚あたり32✖️32のフルカラーの画像なので、配列で表現すると、フルカラーは3つの要素で表現されるので3つの要素を持った一次元の配列を32個(32列)持った二次元の配列が32行あるということになる。
[0,0,0]・・・・・・・・・・・3つの要素を持った配列。
[[0,0,0],[0,0,0]....[0,0,0]]・・・3つの要素の配列を32個持った二次元配列
1 2 32(個)
[[[0,0,0],[0,0,0]....[0,0,0]],・・・上記の配列が32行ある三次元配列
[[0,0,0],[0,0,0]....[0,0,0]],
........
[[0,0,0],[0,0,0]....[0,0,0]]]
すぐ上の三次元配列によって一つの画像は表現されているので、ここから一次元にした場合の要素数を計算すると
32 ✖️ 32 ✖️ 3 で求めることができる。
モデル定義
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(im_size,)))
model.add(Dense(num_classes, activation='softmax'))
モデルコンパイル
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
学習
hist = model.fit(X_train, y_train,
batch_size=32, epochs=50,
verbose=1,
validation_data=(X_test, y_test))
モデル評価
score = model.evaluate(X_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
学習の様子をグラフへ描画
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
plt.title('Loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
CNNの仕組みを使ってMNISTのデータを機械学習にかける
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import RMSprop
from keras.datasets import mnist
import matplotlib.pyplot as plt
# 入力と出力を指定 --- (*1)
im_rows = 28 # 画像の縦ピクセルサイズ
im_cols = 28 # 画像の横ピクセルサイズ
im_color = 1 # 画像の色空間/グレイスケール
in_shape = (im_rows, im_cols, im_color)
out_size = 10
# MNISTのデータを読み込み
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 読み込んだデータをの三次元配列に変換 --- (*1a)
X_train = X_train.reshape(-1, im_rows, im_cols, im_color)
X_train = X_train.astype('float32') / 255
X_test = X_test.reshape(-1, im_rows, im_cols, im_color)
X_test = X_test.astype('float32') / 255
# ラベルデータをone-hotベクトルに直す
y_train = keras.utils.to_categorical(y_train.astype('int32'),10)
y_test = keras.utils.to_categorical(y_test.astype('int32'),10)
# CNNモデル構造を定義 --- (*2)
model = Sequential()
model.add(Conv2D(32,
kernel_size=(3, 3),
activation='relu',
input_shape=in_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(out_size, activation='softmax'))
# モデルをコンパイル --- (*3)
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
# 学習を実行 --- (*4)
hist = model.fit(X_train, y_train,
batch_size=128,
epochs=12,
verbose=1,
validation_data=(X_test, y_test))
# モデルを評価 --- (*5)
score = model.evaluate(X_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
# 学習の様子をグラフへ描画 --- (*6)
# 正解率の推移をプロット
plt.plot(hist.history['accuracy'])
plt.plot(hist.history['val_accuracy'])
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# ロスの推移をプロット
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('Loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
実行結果


このプログラムではCNN(畳み込みニューラルネットワークの仕組みを利用してMNISTのデータを機械学習にかけるプログラムです。MLPより高い精度を叩き出すことができた。
CNNや畳み込み層などの説明すごく分かりやすかった記事
https://yoshi-sun.com/web/python/1950/
MNISTデータ読み込み
(X_train, y_train), (X_test, y_test) = mnist.load_data()
読み込んだデータを三次元の配列に変換
im_color = 1 # 画像の色空間/グレイスケール
in_shape = (im_rows, im_cols, im_color)
out_size = 10
X_train = X_train.reshape(-1, im_rows, im_cols, im_color)
X_train = X_train.astype('float32') / 255
X_test = X_test.reshape(-1, im_rows, im_cols, im_color)
X_test = X_test.astype('float32') / 255
CNNでは、畳み込み層を構成するために、画像の縦、横、色の三次元に変換する必要がある。
[[[0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0]]
[[0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0]]
[[0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0]]
.......
[[0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0][0]]]
このように1ピクセルは行数28,列数1の二次元配列を28個持った三次元の組み合わせによって表現しているから。
そのために、X_train.reshape(-1, im_rows, im_cols, im_color)ではデータを三次元の配列に変換している。ここでは、第一引数に-1を指定し、X_trainの中身を一次元の配列にして、第二引数の28、第三引数の28、第四引数の1を指定することで一次元の配列から28個、28行1列の配列を作り三次元の配列を作成している。
reshapeの引数は
例えば(3,3,2)なら
[[[0,0],[0,0],[0,0]],[[0,0],[0,0],[0,0]],[[0,0],[0,0],[0,0]]]こーなる。中身の0は気にしないで。これは言葉で言うと3個、3行2列の配列を持った配列を作ると言える。
(2,2)なら2行2列の配列に作り直すと行った具合に何行何列の配列を何個もった配列を作るのか考えると分かりやすいと思った。
X_train.astype('float32') / 255では255で要素全体を割ることで中身は色情報を持ち、0~255で表現されているので色情報を0.0~1.0で表現することができるからです。
ラベルデータをohe-hotベクトルに直す
y_train = keras.utils.to_categorical(y_train.astype('int32'),10)
y_test = keras.utils.to_categorical(y_test.astype('int32'),10)
keras.utils.to_catogorical()でラベルデータを渡し、10クラスで表現したものに変換。
今回は手書き数字の判定なので0~9の10種類のラベルデータが存在するので一つ一つのデータを10要素持つ配列で表現している。
CNNモデルの定義
model = Sequential()
model.add(Conv2D(32,
kernel_size=(3, 3),
activation='relu',
input_shape=in_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(out_size, activation='softmax'))
畳み込みとは
入力画像のピクセル範囲に対してフィルターを適用していく作業。
カーネルサイズが3✖️3なら画像のピクセルデータの左上から順に3✖️3を1✖️1で表現するように変換していく。

このケースでは一つのフィルターしか使っていないが32や64をConv2Dの第一引数に指定することでフィルター数を指定できる。28✖️28のデータに3✖️3のフィルターをかけていくと26✖️26のデータに畳み込むことができる。
Conv2D()で畳み込み層の作成、MaxPooling2D()がプーリング層の作成。Flatten()では入力を平滑化(一次元の配列に変換)している。畳み込み層では、画像の特微量の畳み込みを行う。どう言うことかと言うと画像の各部分にある特徴を調べるということ。そして、プーリング層では、画像データの特徴を残しつつ圧縮する。圧縮することで、その後の処理がしやすくなる。画像解析のときのような流れで画像の特徴を捉えて圧縮、平滑化(ぼかし処理)を行い全結合層へとデータを流し込みイメージなのかな。
Conv2D(32, kernel_size=(3,3)では3✖️3のフィルターを32枚使うという意味。フィルタ数は、「16,32,64,128,256,512」枚などが使われる傾向にあるようだが複雑そうならフィルタ数を多めに、簡単そうならフィルタ数を少なめで試してみるといいらしい。
input_shapeで入力を指定。今回は28✖️28のグレースケールの画像なので(28, 28 ,1)を指定しているが例えば128✖️128のRGB画像であれば(128, 128, 3)と指定する。
MaxPooling2D()では平均値を取るものもあるが、今回は最大値を取るプーリングを行っている。pool_size=(2.2)を指定しており、これは2✖️2のプールサイズをとっていることになる。

こんな感じ。
Flatten()では各フィルタによって特徴が分割されたものを一つにまとめるため、一次元に変換する。
そして、Denseで全結合層へとデータを流し込んでいく。
モデルコンパイル
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
学習を実行
hist = model.fit(X_train, y_train,
batch_size=128,
epochs=12,
verbose=1,
validation_data=(X_test, y_test))
validation_data=(X_test, y_test)を指定することで返り値としてhistoryオブジェクトにepoch毎での訓練データでの評価とvalidation_dataに指定したデータでの評価の結果を格納してくれる。
モデルを評価
score = model.evaluate(X_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
学習の様子をグラフに描画
# 正解率の推移をプロット
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# ロスの推移をプロット
plt.title('Loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
hist.historyのキーで'val'とついているのがvalidation_dataのデータを評価した結果、ついてないのが訓練用データでの評価結果。