python 自分で用意した手書き数字の判定
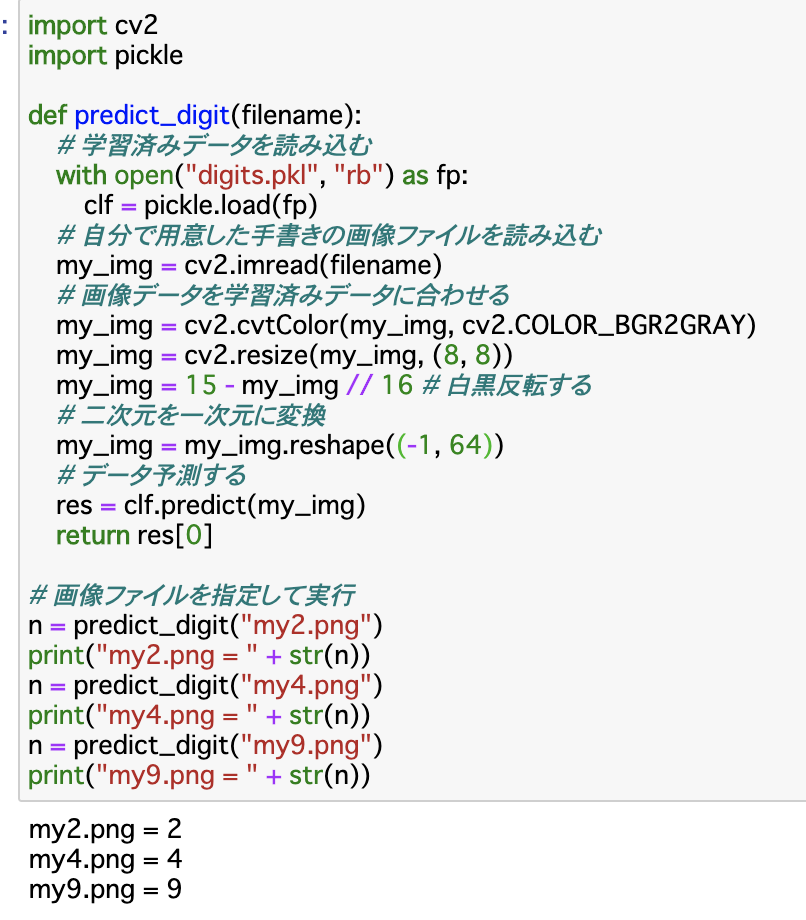
今回は先日作成した手書き数字の学習済みデータを用いて自身で作成した手書き数字の画像を判定できるか試して見た。
前提としてここで使用する学習データは「python 手書き数字の判定」で作成したものである。
predict_digit()関数以外の部分は特に内容がないのでこの関数について記述していく。
predict_digit()
with open("digits.pkl", "rb") as fp:
clf = pickle.load(fp)
上記でdigits.pklという学習済みデータを"rb"を指定してバイナリ形式の読み込み用で開いている。
pickle.load()でデータが格納された変数を渡し、変数clfに格納。
my_img = cv2.imread(filename)
手書きファイルの読み込み。
my_img = cv2.cvtColor(my_img, cv2.COLOR_BGR2GRAY)
my_img = cv2.resize(my_img, (8, 8))
my_img = 15 - my_img // 16
読み込んだファイルをグレイスケールに変換してサイズを8✖️8ピクセルに変換。
今回使用する学習済みデータは8✖️8ピクセルのデータを扱っているためそれに合わせているのだと思う。
my_img = 15 - my_img // 16
この部分では今回使用する学習モデルは0~16の値で文字を判定していて黒い部分を0、16に近くにつれて白を表しているため、255で表されている部分を0に変えるためにリサイズした画像データから15を引いて16で割っている。
リサイズ後の画像データ(my2.png)

白黒反転させた画像データ(my2.png)

リサイズのデータで255(白)を表現していた部分が0(黒)で表現されていて、文字の部分が15で表現されており、0~16の値で画像データを表現することができた。
my_img = my_img.reshape*1
このままでは画像データが二次元のままなので一次元配列にする。
reshape(-1,64)は第一引数の-1で配列を1行にして、第二引数の64で1行64列の配列を作成している。64を指定しているのは8✖️8のデータなので64でひとまとまりだからである。
res = clf.predict(my_img)
return res[0]
データを予測し予測結果を呼び出し元に返している。
*1:-1, 64