python カメラ画像から赤色成分だけ表示
import cv2
import numpy as np
# Webカメラから入力を開始
cap = cv2.VideoCapture(0)
while True:
# 画像を取得
_, frame = cap.read()
# 画像を縮小
frame = cv2.resize(frame, (500,300))
# 青と緑の成分を0に (NumPyのインデックスを利用)---(*1)
frame[:, :, 0] = 0 # 青要素を0
frame[:, :, 1] = 0 # 緑要素を0
# ウィンドウに画像を出力 --- (*2)
cv2.imshow('RED Camera', frame)
# Enterキーが押されたらループを抜ける
if cv2.waitKey(1) == 13: break
cap.release() # カメラを解放
cv2.destroyAllWindows() # ウィンドウを破棄
実行結果

RGBのR(赤色)の値のみ画像に表示している。
webカメラの入力開始
cap = cv2.VideoCapture(0)
whileでフレームごとの画像出力
while True:
# 画像を取得
_, frame = cap.read()
# 画像を縮小
frame = cv2.resize(frame, (500,300))
# 青と緑の成分を0に (NumPyのインデックスを利用)---(*1)
frame[:, :, 0] = 0 # 青要素を0
frame[:, :, 1] = 0 # 緑要素を0
# ウィンドウに画像を出力 --- (*2)
cv2.imshow('RED Camera', frame)
# Enterキーが押されたらループを抜ける
if cv2.waitKey(1) == 13: break
VideoCapture()で生成されたオブジェクトにread()メソッドでワンフレームごとの画像を取得。
大きい画像は必要ないのでresize()で縮小。
numpyを使っての画像処理はRGB画像は高さ、幅、色の三次元配列。白黒画像は高さ、幅の二次元配列。
frame[:,:,0] = 0
ここでは青色の要素を0にしており、:このコロンの意味は全てという意味である。画像データは高さ、幅、色なので[:(高さ), :(幅), 0(色)]ということになる。つまり全ピクセルの色データの0番目の要素を0にする処理をしている。色は通常R,G,B(0,1,2)の順になっているがopencvでの画像はBGRになっているので今回の場合Bの部分の要素を0にすることができる。
frame[:,:,1] = 0
上記と同じで色の1番目の要素を0に指定している。
上記二つの処理によってR、つまり赤色の要素以外を消すことができた。
そしてcv2.imshow()でウィンドウを表示してcv2.waitKey()でenterを押された時処理を止める。
release()はカメラを閉じる。
cv2.destoryAllWindow()はウィンドウを閉じる。
python webカメラの起動
import cv2
import numpy as np
# Webカメラから入力を開始 --- (*1)
cap = cv2.VideoCapture(0)
while True:
# カメラの画像を読み込む --- (*2)
_, frame = cap.read()
# 画像を縮小表示する --- (*3)
frame = cv2.resize(frame, (500,300))
# ウィンドウに画像を出力 --- (*4)
# ESCかEnterキーが押されたらループを抜ける
k = cv2.waitKey(1) # 1msec確認
if k == 27 or k == 13: break
cap.release() # カメラを解放
cv2.destroyAllWindows() # ウィンドウを破棄
opencvでカメラの映像や動画ファイルを処理するにはcv2.VideoCapture()を使う。
動画ファイルを読み込むには引数にパスを指定する。
今回はカメラの映像を読み込みたいのでカメラの番号を指定する。カメラの番号とは基本は0から順に割り振られていて、内臓カメラ0,USBで追加のカメラを接続すると1といった形になる。
今回のプログラムでは繰り返し画像を読み込むことで、動画をウィンドウに出力している。
カメラの画像を読み込む
read()メソッドで動画ファイルの1フレームごとのbool値(True,False)、画像データのタプルが返り値として返される。ファイルの取得が終わるとFalseとNoneを返す。
画像を縮小表示する
大きな画像は必要ないので縮小するためにcv2.resize()
ウィンドウに画像を出力
opencvには動画を再生させる特別なメソッドはないのでcv2.imshow()で画像を表示していく。第一引数は表示するフレームの名前なのでなんでもいい、第二引数は画像データ。
ESCかEnterキーが押されたらループを抜ける
cv2.waitkey(1)は1ミリ秒の出力を意味しておりその間に指定したキーが入力されると処理を止めるというものである。27はesc、13はEnterどちらかを押すとbreakが実行されwhile処理を終了する。
その後
cap.release() # カメラを解放
cv2.destroyAllWindows() # ウィンドウを破棄
それぞれでカメラを終了しウィンドウを閉じている。
python 抽出した数字の判定

学習済みデータ読み込み
with open("digits.pkl", "rb") as fp:
clf = pickle.load(fp)
作成した学習済みデータを読み込んで数字の判定をしていく。
画像から領域を読み込む
detect_zip.pyというファイルを別に用意しており、そのファイルのdetect_zipno関数を呼び出し。
detect_zipno関数は引数で渡した画像データから郵便番号の領域を抽出してくれる関数。
cntsには抽出した領域のリスト(x,y,w,h)
imgには抽出した画像データ。
読み込んだデータをプロット
for i, pt in enumerate(cnts):
x, y, w, h = pt
# 枠線の輪郭分だけ小さくする
x += 8
y += 8
w -= 16
h -= 16
# 画像データを取り出す
im2 = img[y:y+h, x:x+w]
# データを学習済みデータに合わせる
im2gray = cv2.cvtColor(im2, cv2.COLOR_BGR2GRAY) # グレイスケールに
im2gray = cv2.resize(im2gray, (8, 8)) # リサイズ
im2gray = 15 - im2gray // 16 # 白黒反転
im2gray = im2gray.reshape*1 # 一次元に変換
# データ予測する
res = clf.predict(im2gray)
# 画面に出力
plt.subplot(1, 7, i + 1)
plt.imshow(im2)
plt.axis("off")
plt.title(str(res))
枠線を取り除く。

上記は枠線を取り除く処理を行わなかった時の出力結果である。
判定ができていないので枠を取り除く。
x,y,w,hそれぞれになんの値を入れると枠が無くなるのかは数字を入れながら手探りでやった。
・画像をグレースケールに変換.。
・学習済みデータに合わせるために画像を8✖️8ピクセルにリサイズ。
・白黒反転させて0~16までの値で表現(0に近いほど黒、16に近いほど白い)
・二次元配列を一次元に変換。一つの画像は8✖️8の合計64ピクセルの要素からなるので1行64列の一次元配列に変換。
あとは予測結果をタイトルに表示して終わり。
*1:-1, 64
python はがきから郵便番号の輪郭取得

実行結果(左側元画像、右側出力結果)

まずif __name__ == '__main__':について
これは別ファイルからこのファイルがimportされた時と同時に実行されないようにしているものである。
例
hello.py
if _ _ name _ _ == '_ _main_ _':がない場合。
if _ _ name _ _ == '_ _main_ _':がある場合。
今回の処理はほとんどdetect_zipno()関数内で処理しているのでこの関数に関して細かく見ていく。
画像読み込み。無駄な領域を省く。
img = cv2.imread(fname)
# 画像のサイズを求める
h, w = img.shape[:2]
# ハガキ画像の右上のみ抽出する --- (*1)
img = img[0:h//2, w//3:]
画像ファイル.shapeで画像の高さ、幅、色を取得できる。
[:2]を指定することで取得した配列の最初の要素からインデックス番号が1の要素までを取得し変数に格納。[:2]を指定しなければ色の情報も取得してしまうので指定している。
img[0:h//2, w//3:]では画像の右上のみを抽出しており、今回ははがきの郵便番号を扱うことが分かっているので無駄な領域を省いていく。
画像の切り抜きは[y1:y2, x1:x2]のように指定する。
今回はw//3:とx2となる部分は記述はないのでx2は一番後ろまでを意味しており画像の幅を指定しているのと同じ結果になる。[0:h//2, w//3:w]でも同じ結果。
#リストについて補足
スライスという機能を使うとリストの一部を取得することができる。
リスト名[開始インデックス:終了インデックス] 開始インデックスから終了インデックスの手前までの要素を取得する。 開始インデックスと終了インデックスには負の値を指定することも可能。 開始インデックスを省略すると最初の要素から取得し、終了インデックスを省略すると最後の要素まで取得する。
【使用例】
list_number = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print list_number[1:5]
print list_number[1:-5]
print list_number[-5:9]
print list_number[:5]
print list_number[5:]
print list_number[:-5]
print list_number[-5:]
print list_number[:]
【実行結果】
[1, 2, 3, 4]
[1, 2, 3, 4]
[5, 6, 7, 8]
[0, 1, 2, 3, 4]
[5, 6, 7, 8, 9]
[0, 1, 2, 3, 4]
[5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]画像の二値化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (3, 3), 0)
im2 = cv2.threshold(gray, 140, 255, cv2.THRESH_BINARY_INV)[1]
グレースケールに変更。
cv2.GaussianBlur()関数で平滑化(ぼかし処理)
カーネルサイズサイズ、標準偏差が大きくなるとぼかし具合が強くなる。
標準偏差に0を指定するとカーネルサイズから自動で標準偏差を指定してくれるので細かな調整が必要ない場合は0で十分。
cv2.threshold()で二値化。
(画像ファイル, しきい値, しきい値以上時の割り当てる値,どのように二値化を行うかの指定)
そして、返される値が二次元配列で二値化したデータはインデックス番号が1の部分にあるのでthreshold()[1]のように指定している。
輪郭の抽出
cnts = cv2.findContours(im2,
cv2.RETR_LIST,
cv2.CHAIN_APPROX_SIMPLE)[1]
cv2.findContours()関数で輪郭の抽出。
引数は(画像データ, 抽出方法, 近似手法)の順で指定。
これも必要なデータはインデックス番号1にあるので[1]を指定。
第三引数のcv2.CHAIN_APPROX_SIMPLEでは不必要な点を削除し、必要最低限の点のみを返している。cv2.CHAIHN_APPROX_NONEを指定すると輪郭上の全ての点を返す。
抽出したリストから外接する長方形のリストに変換
result =
for pt in cnts:
x, y, w, h = cv2.boundingRect(pt)
# 大きすぎる小さすぎる領域を除去 --- (*5)
if not(50 < w < 70): continue
result.append([x, y, w, h])
cv2.boundingRect()で輪郭に外接する長方形のタプルを返す
返り値は(左上からのx座標,y座標,幅,高さ)
appendメソッドはリストの末尾に要素を追加する。
抽出した輪郭が左側から並ぶようにソート(並び替え)
result = sorted(result, key=lambda x: x[0])
これを行うことで左から郵便番号の情報を扱えるようになる。
sorted()は並び替えの処理をするのに使用。
デフォルトは昇順、第二引数にreverse=Trueを指定すると降順になる。
二次元配列では今回のように第二引数のkeyに関数を指定するとソートされる前に各要素に適用させることができる。指定しないとそれぞれのリストの先頭の要素の小さいもの順にソートされる。
今回指定しているlamda関数は無名関数であり、xで要素を一つずつ受け取りx[0]の要素を返す処理をしている。つまり各要素の先頭の要素で比較しソートしている。
(この場合はkeyを指定しなくても同じ結果を得られる)
抽出した輪郭が近すぎるものを除去
result2 =
lastx = -100
for x, y, w, h in result:
if (x - lastx) < 10: continue
result2.append([x, y, w, h])
lastx = x
抽出したデータを見ると枠線の内側と外側で別の輪郭として抽出している部分があった。
そのため要素のx座標の距離が近すぎるものを除去して新しいリストを作成。
このfor文ではその要素のxから一つ前の要素のxを引いた時10より小さい時、新しいリストに加えないようにしている。
一番最初に定義している-100の値は一番最初の要素のxをから引いた値が10以上になればなんでもいいと思う。
緑の枠を描画
for x, y, w, h in result2:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 3)
return result2, img
cv2.rectangle()で描画。
returnで値を呼び出し元に返す。
python 輪郭の値取得後、外接する長方形の値の取得
先日の輪郭領域の抽出で輪郭の値を取得した後に外接する長方形の値を取得する部分がよく理解できていなかったので再度調べてみた。
cv2.findcontours()関数で輪郭を出力してcv2.boundingRect()関数で輪郭に外接する長方形の値を取得できる。
cv2.findcontours()の返り値は輪郭の座標点が(左上からのx座標 ,y座標)格納されていてcv2.boundingRect()では外接する長方形を出力するのでfindcontours()で取得した輪郭の座標点を全て内側になるような(覆うような)長方形の値が取得できる。
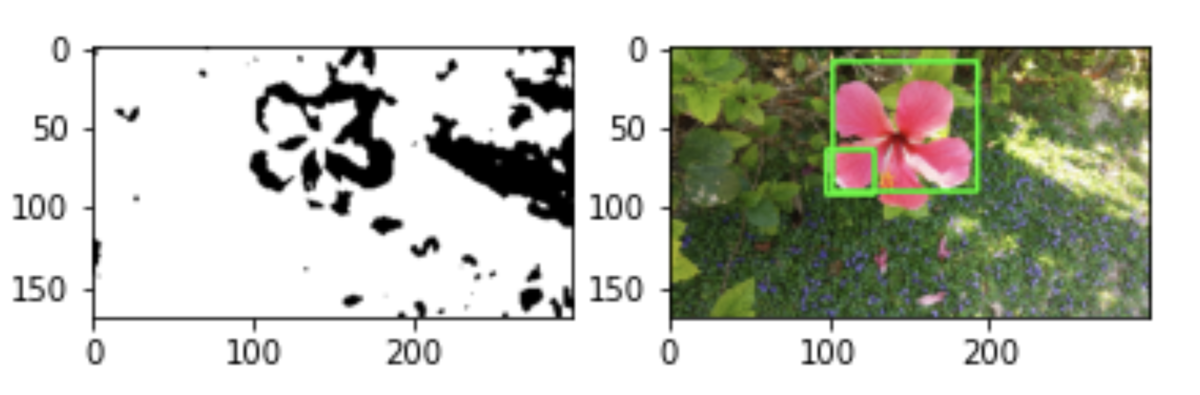
python 画像の領域の抽出(輪郭)

モジュールインポートと画像読み込みは省く。
・色空間の二値化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (7, 7), 0)
im2 = cv2.threshold(gray, 140, 240, cv2.THRESH_BINARY_INV)[1]
画像の平滑化(ぼかし処理)について
ぼかす処理を行うのは複雑で細かい模様などを検出しないように、画像をぼかしている。opencvには画像をぼかすための関数がいろいろ用意されていて今回使用するのはcv2.GaussianBlur()関数である。この関数はホワイトノイズの除去に適している。
例
平滑化(ぼかし処理を行った場合)

平滑化を行わなかった場合

今回のcv2.GaussianBlur()では上記の画像を見てわかる通り、画像をぼかし細かい模様を除去していることがわかる。
記述については
cv2.GaussianBlur(img, (ax, ay), sigma_x)
第一引数には画像、第二引数には平滑化(ぼかし処理)をする画素の周囲のサイズをピクセル指定する、この時値は奇数でないといけない。第三引数には横方向の標準偏差を指定する。0の場合はカーネルサイズから自動で計算される。
例
第二引数(1,1)の時

第二引数(7,7)の時(今回)

第二引数(33,33)の時

第二引数(55,55)の時
そして、画像の平滑化を行った後にデータをcv2.threshold()関数で二値化している。二値化とは画像のしきい値より大きければ白、小さければ黒を割り当てる処理、要するに白か黒に分ける。
画像の二値化を行うにはcv2.threshold()関数を使い、第一引数にはグレースケールの画像を指定、第二引数にはしきい値を指定、第三引数にはしきい値以上の値を持つ値に対して割り当てる値を指定、第四引数にはどのように二値化を行うのかを指定し、THRESH_BINARY_INVを指定した場合、しきい値よりも大きな値であれば0、それ以外はmaxval(第三引数)の値にする。
・画面左側に上記で処理した画像を描画
plt.subplot(1, 2, 1)
plt.imshow(im2, cmap="gray")
subplotでは複数のプロットを一枚の画像に貼り付けており
subplot(行,列,左上から何番目に貼り付けるか)のように指定している。
・輪郭の抽出
cnts = cv2.findContours(im2,
cv2.RETR_LIST,
cv2.CHAIN_APPROX_SIMPLE)[1]
輪郭を抽出するにはcv2.findContours()関数を使用する。
cv2.findColtours(image, mode, method)のように記述する。
第一引数は入力画像、第二引数は抽出方法、第三引数は近似手法を指定する。
返り値は輪郭リスト、階層情報が返される。
第二引数は輪郭の抽出方法を指定していて、今回のcv2.RETR_LISTは単純に輪郭を検出するものである。
第三引数の近似手法で指定しているcv2.CHAIN_APPROX_SIMPLEは不必要な点を削除し必要最低限の点だけを返す。cv2.CHAIN_APPROX_NONEもあるがそれは輪郭上の全ての点を保持するものである。近似手法についてはふんわり分かった気がするがここでは一般的にCHAIN_APPROX_SIMPLEを使用することが多いらしい。
・抽出した輪郭を描画
for pt in cnts:
x, y, w, h = cv2.boundingRect(pt)
# 大きすぎたり小さすぎたり領域を除去
if w < 30 or w > 200: continue
print(x,y,w,h) # 結果を出力
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.boundingRect()で輪郭に外接する長方形を計算できる。
引数
・numpy配列、輪郭を渡す。
返り値
・(左上のx座標,y座標, 幅, 高さ)のタプル(タプルは(0,1,2,3)こんなやつ)。輪郭に外接する長方形の値。
cv2.rectangleで枠を描画。
・画面右側に抽出結果を描画
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()
savefig()で画像を保存しているがdpiパラメータに値を指定することで高解像度で保存することができる。
例
dpiを指定しない場合(デフォルト)
dpi=200を指定した場合
