APIを呼び出すwebアプリの作成

index.html

実行結果

今回のプログラムでは
hanamichi-sukusuku.hatenablog.com
上記で作成した機械学習の機能を持つwebサーバーを使用して、APIを呼び出すwebアプリを作成していく。
webサーバーでは既にURLで渡されたパラメーターを機械学習にかけるようになっている。
今回必要なのはhtml/css, javascriptを用いたindex.htmlファイルを作成する。
入力欄とボタンの作成
<DOCTYPE html>
<h1>テキストのジャンル判定</h1>
<div>
<textarea id="q" rows="10" cols="60"></textarea>
<br><button id="qButton">判定</button>
<div id="result"></div>
</div>
判定ボタンがクリックされたときの処理(JS)
<script>
const qs = (q) => document.querySelector(q)
window.onload = () => {
const q = qs('#q')
const qButton = qs('#qButton')
const result = qs('#result')
// 判定ボタンを押した時 --- (*1)
qButton.onclick = () => {
result.innerHTML = "..."
// APIサーバに送信するURLを構築 --- (*2)
// APIにアクセス --- (*3)
fetch(api).then*1で受け取りjson形式で次のthen()の処理に返り値を渡している。then()メソッドでは複数の処理を繋ぎ、順番に実行していく。
then((data)=>...ではhtmlで結果を出力するdiv要素にラベルデータと確率のデータを文字列で追加している。
*1:res) => {
}).then((data) => {
// 結果を画面に表示 --- (*4)
result.innerHTML =
data["label"] +
"<span style='font-size:0.5em'>(" +
data["per"] + ")</span>"
})
}
}
</script>
const qsで無名関数を定義。引数に指定したidの要素を取得する。
qButton.onclickで判定ボタンが押されたときの処理を記述。
result.innerHTMLでAPIサーバーから出力が返ってくるまで"..."と表示する。
const apiで変数apiにAPIサーバーに送信するURLを構築。encodeURIComponent()では引数に指定した文字列をURLで使用できる形式に変換(エンコード)するためのもの。URLでは日本語は使用できないのでパラメーターとして送る文字列をこれによって変換している。
fetch()メソッドでは非同期で引数に指定したURLにHTTPリクエストを送信している(デフォルトはGET)。responseオブジェクトをfetch(api)からthen((response
機械学習の機能を持つwebサーバーの作成
webサービスに機械学習のシステムを組み込むためにはwebサーバーと機械学習サーバーを異なる形で動かすことやwebサーバー内で機械学習のシステムを持たせる方法になどによってwebサービスに機械学習のシステムを組み込むことができる。
今回はまず、pythonで機械学習の機能を持つwebサーバーを作成していく。

実行結果

ソースコードでは見やすさの観点からjupyter notebookでのコードになっているが実行はコマンドラインから行う。
実行結果では「野球を見るのは........楽しみです。」という文章をプログラムに渡して、json形式でその結果が返されている。jsonなので日本語がエンコードされていまっているがデコードすると「スポーツ」となる。
hanamichi-sukusuku.hatenablog.com
ここで使用しているプログラムは同じディレクトリ内にある、上記で作成したファイル(my_text.py)のcheck_genre関数を使用し、URLで渡した文章を分類している。
モジュールインポート
jsonモジュールはpythonでjson形のデータを扱う時に利用する。
flaskはwebサーバーを手軽に作成できるフレームワーク。
from flask import requestではURLからパラメーターの取得ができたりするためにインポート。
import my_textは上記で記述した通り、事前に作成した機械学習のプログラム。
ポート番号、HTTPサーバーの起動
TM_PORT_NOはポート番号で8888を定義しているがもし、別のアプリで8888番を使っている場合には他の番号に変更する。
flask.Flask(__name__)でFlaskオブジェクトを生成する。
ターミナル上でプログラムが正しく実行されるかのテスト
label, per, no = my_text.check_genre("テスト")
print("> テスト --- ", label, per, no)
この出力結果はターミナル上に出力される。
無事出力されたので次に進む。
ローカルサーバー起動
appにはFlaskオブジェクトが格納されているのでapp.run()でサーバーを起動。
引数のdebug=Trueではデバッグを出力するようにしている。
host='0.0.0.0.'を指定しないと外のネットワークから接続ができないらしい。パソコンでこのローカルサーバーを立ち上げ、別の端末からこのサーバーにアクセスするために必要。実際に自身のスマホから接続できた。
portはポート番号に指定。
ルート(/)にアクセスしたときの処理
@app.route('/', methods=['GET'])
def index():
with open("index.html", "rb") as f:
return f.read()
@app.route()でルートパスにアクセスされた時の後述する関数を実行するようにしている。methods=['GET']でGETリクエストを指定。
index()関数では同階層のindex.htmlファイルを読み込み、表示している。

http://localhost:8888/このURLにアクセスした時の画像。
/apiにアクセスしたときの処理
# URLパラメータを取得 --- (*3)
q = request.args.get('q', '')
if q == '':
return '{"label": "空です", "per":0}'
print("q=", q)
# テキストのジャンル判定を行う --- (*4)
label, per, no = my_text.check_genre(q)
# 結果をJSONで出力
return json.dumps({
"label": label,
"per": per,
"genre_no": no
})
@app.route()で/apiにアクセスした時、後述する関数を実行するようにしている。ここでもmethods=['GET']でGETリクエストを指定。
request.args.get()ではURLからパラメーターをしている。第一引数の'q'はキー。URLで'q'をキーとするパラメーターを取得し変数qに格納。
my_text.check_genre()では事前の作成したmy_text.pyからcheck_genre()関数を使用している。上記のリンクを見ればわかるが、この関数では渡した文章を機械学習で分類し、どのラベルを示すものか、確率、ラベルデータの番号をそれぞれ返す。
return json.dumps()で第一引数に辞書を渡すとjson文字列として出力されたものを返す。
一番上の実行結果には
http://localhost:8888/api?q=(テキスト)という形でアクセスしたときの実行結果を表示している。
文章を指定してTF-IDFに変換しディープラーニングで判定


実行結果

このプログラムではMLPを利用して文章を指定しどんなジャンルの文章なのか判定するプログラム。
インポートしているtfidfモジュールは下記のリンクで作成したものを使用する。
TF-IDFの手法でモジュール作成 - hanamichi_sukusukuのブログ
独自テキストの定義、TF-IDFの辞書を読み込む
text1 = """
野球を観るのは楽しいものです。
試合だけでなくインタビューも楽しみです。
"""
text2 = """
二口あるモバイルバッテリがあると便利。
"""
text3 = """
幸せな結婚の秘訣は何でしょうか。
夫には敬意を、妻には愛情を示すことが大切。
"""
# TF-IDFの辞書を読み込む --- (*2)
tfidf.load_dic("text/genre-tdidf.dic")
""" """は中身の改行をそのままの状態で扱うことができる。改行文字\nで表記した場合と同じ。
tfidf.laod_dic()は作成したtfidfモジュールのload_dic()関数である。この関数では引数で渡したパスから保存した単語辞書や単語の出現頻度を格納してあるデータをtfidfモジュール内で読み込み、グローバル変数として使用できるようにするもの。これによりtfidfモジュールから単語辞書、全文章での単語の出現頻度、livedoorニュースコーパスの文章をIDで表現したデータの3つが使用できるようになる。
モデル定義
nb_classes = 4
dt_count = len(tfidf.dt_dic)
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(dt_count,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(nb_classes, activation='softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
model.load_weights('./text/genre-model.hdf5')
dt_countはMLPの入力レイヤーでの入力数を格納している。tfidf.dt_dicはlivedoorニュースコーパスを使用した4ジャンルの文章全体での単語の出現頻度が格納されているデータ。一つの文章はこのdt_dicにある単語数で表現されるのでこの要素数が入力数になる。具体的には文章中の単語を辞書のidで表現し、その出現頻度と希少性を掛け合わせたTF-IDFのデータを使い、モデルに学習させるので入力数としては辞書の単語数(要素数)を使用する。
model.load_weights()で重みデータを読み込んでいる。この重みデータはlivedoorニュースコーパスのテキストを事前にMLPで学習し、その時の重みデータを保存したもの。
関数の呼び出し
if __name__ == '__main__':
check_genre(text1)
check_genre(text2)
check_genre(text3)
check_genre()関数
def check_genre(text):
# ラベルの定義
LABELS = ["スポーツ", "IT", "映画", "ライフ"]
# TF-IDFのベクトルに変換 -- (*5)
data = tfidf.calc_text(text)
# MLPで予測 --- (*6)
pre = model.predict(np.array([data]))[0]
n = pre.argmax()
print(LABELS[n], "(", pre[n], ")")
return LABELS[n], float(pre[n]), int(n)
この関数では引数で受け取ったテキストをモデルに学習させ予測結果を出力するためのもの。
tfidf.calc_text()でtfidfモジュール内の単語辞書を更新せずにTF-IDFベクトルに変換する。(単語辞書の要素数で表現されたTF-IDFベクトルデータ)
model.predict()で結果を予測。
argmax()で予測結果から最も値が大きいインデックス番号を返す。
LABELSに定義している要素のインデックスとラベルデータのインデックスは対応しているので予測したラベルと確率を出力。
・このプログラムでは学習ずみの単語しかベクトル化できない。今回作成したモジュールでは、livedoorニュースコーパスに出てこない、未知語を見つけると単語をなかったことにする処理にしてあるため学習したことない単語が多く出てくるほど、判定結果が悪くなる。そこで、未知語が出てきたら覚えておいて、改めて学習をやり直すなど、工夫が必要になる。
NaiveBayesでTF-IDFで作成したデータベースを学習

実行結果

このプログラムではNaiveBayes(ナイーブベイズ)を利用してTF-IDFのデータベースを学習している。
TF-IDFのデータベースを読み込む
data = pickle.load(open("text/genre.pickle", "rb"))
y = data[0] # ラベル
x = data[1] # TF-IDF
hanamichi-sukusuku.hatenablog.com
genre.pickleに関しては上記でlivedoorニュースコーパスのデータを利用してTF-IDFベクトルに変換したデータを作成している。
学習用とテスト用に分ける
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2)
ナイーブベイズで学習
model = GaussianNB()
model.fit(x_train, y_train)
評価して結果を出力
y_pred = model.predict(x_test)
acc = metrics.accuracy_score(y_test, y_pred)
rep = metrics.classification_report(y_test, y_pred)
print("正解率=", acc)
print(rep)
metrics.classification_report()では正解データと予測データを渡すことでprecision(適合率)やrecall(再現率)などのそれぞれのデータを比較したときの詳細をみることができる。
metrics.classification_report()見方
y_test = [0,0,0,1](正解)
y_pred = [0,0,1,1](予測)
例えばmetrics.classification_report(y_test, y_pred)このような場合

precision
・precision(適合率)は0と予測した2つはどちらも正解なので適合率1.00。
・1と予測した2つはそのうちの1つが正解なので適合率0.50。
recall
・recall(再現率)は正解が0だった3つのうち、正しく0だと予測されたものは2つなので再現率0.67。
・正解が1だった1つを予測結果で予測できているので再現率1.00。
f1-score
fi-scoreは調和平均。
support
正解の要素数。
文章をTF-IDFのデータベースに変換
このプログラムではlivedoorニュースコーパスを利用する。
スポーツ、IT、映画、ライフの4つに分けたデータベースを生成する。

実行結果
genre.pickleというファイルにTF-IDFに文章を変換したデータを格納し保存する。
tfidfモジュール内で生成した単語辞書、テキストをIDで表現したデータ、全文章での単語の出現頻度のデータも保存。
ファイル読み込み
y =
x =
# ディレクトリ内のファイル一覧を処理 --- (*1)
def read_files(path, label):
print("read_files=", path)
files = glob.glob(path + "/*.txt")
for f in files:
if os.path.basename(f) == 'LICENSE.txt': continue
tfidf.add_file(f)
y.append(label)
# ファイル一覧を読む --- (*2)
read_files('text/it-life-hack', 1)
read_files('text/movie-enter', 2)
read_files('text/dokujo-tsushin', 3)
read_files()関数に事前にlivedoorニュースコーパスからtextディレクトリに作成しておいたそれぞれのファイルのパスとラベルにする値を渡す。
glob.glob()でファイルの中身のテキストファイル名を全て取得。
os.path.basename()では引数に渡したパスからファイル名を取得してくれる。LICENSE.txtの場合はcontinue。
tfidf.add_file()は自作したモジュールから関数を使用している。
hanamichi-sukusuku.hatenablog.com
上記のリンクでモジュールを作成している。
tfidf.add_file()
def add_file(path):
'''テキストファイルを学習用に追加する''' # --- (*6)
s = f.read()
add_text(s)
引数で受け取ったパスのファイルを読み取り用で開き、read()で読み込む。
add_text()ではテキストをIDリストに変換してくれる。
tfidf.add_file()関数を実行すると単語辞書、テキストをIDで表記したデータを生成してくれる。
モジュールの詳細は上記リンク。
y.append()でラベルデータ作成。
TF-IDFベクトルデータをxに格納
x = tfidf.calc_files()
tfidf.calc_files()ではTF-IDFの手法で文章中に出現した単語の出現頻度を重要も考慮した形でのデータに変換し呼び出し元に返す。同時に関数で全テキストデータでの単語の出現頻度のデータも生成している。
このxの中身を確認すると

TF-IDFでの単語の重要度を考慮した形でのデータになっている。
データの保存
pickle.dump([y, x], open('text/genre.pickle', 'wb'))
tfidf.save_dic('text/genre-tdidf.dic')
print('ok')
pickle.dump()でラベルデータ、TF-IDFベクトルに変換したテキストデータをtextディレクトリにgenre.pickleという名前のファイルを作成し保存。
tfidf.save_dic()では引数に指定したパスに単語辞書、テキストをIDで表現したデータ、全文章での単語の出現頻度のデータ(一つのファイルで複数回同じ単語が出現しても足し合わせない。一度でも複数でもその単語をキーとする値は1)を保存する。
TF-IDFの手法でモジュール作成
TF-IDFとは
BOW(Bag-of-Words)のように文章をベクトルデータに変換する手法のこと。BOWの手法では単語の出現頻度によって文章を数値化していた。TF-IDFでは単語の出現頻度に加えて、文章全体における単語の重要度も考慮するもの。TF-IDFは文書内の特徴的な単語を見つけることを重視する。その手法として、学習させる文章全ての文書で、その単語がどのくらいの頻度で使用されているかを調べていく。例えば、ありふれた「です」、「ます」などの単語の重要度を低くし、他の文書では見られないような希少な単語があれば、その単語を重要なものとみなして計算を行う。つまり、出現頻度を数えるだけではなくて、出現回数が多いもののレートをさげ、出現頻度の低いもののレートをあげるような形で単語をベクトル化していく。TF-IDFを使用することで、単語の出現頻度を数得るよりも、ベクトル化の精度向上が期待できる。


実行結果

4つ目のデータを見てみると0.7954...と高い数値を表しているものがある。これは日曜という単語を示しており、他の文章で使用されていない特徴的な単語なため数値が高くなっていることがわかる。
このプログラムでは文章中の単語の重要度に注目したTF-IDFを用いて、単語ごとの希少性を示したデータを出力していく。
TF-IDFを実践するにはscikit-learnの「TfrdVectorizer」も有名だが、追加で日本語への対応処理が必要なので今回は用いていない。
MeCabの初期化と辞書などの定義
import MeCab
import pickle
import numpy as np
# MeCabの初期化 ---- (*1)
# グローバル変数 --- (*2)
word_dic = {'_id': 0} # 単語辞書
dt_dic = {} # 文書全体での単語の出現回数
files = # 全文書をIDで保存
word_dicは単語辞書。単語をキーとして値にidを持つ。
dt_dicは文書全体での単語の出現回数を持つ。一つの文章に複数同じ単語が出現しても1回でカウントする。
filesは全文書をIDで保存する。一つ一つの文章をIDで表現したデータを格納する配列。
モジュールテスト
if __name__ == '__main__':
add_text('雨')
add_text('今日は、雨が降った。')
add_text('今日は暑い日だったけど雨が降った。')
add_text('今日も雨だ。でも日曜だ。')
print(calc_files())
print(word_dic)
add_text()関数
def add_text(text):
'''テキストをIDリストに変換して追加''' # --- (*5)
ids = words_to_ids(tokenize(text))
files.append(ids)
words_to_ids()関数からは渡したテキストをIDで表現した配列が返される。
それをfilesに追加。
tokenize()関数
def tokenize(text):
result =
word_s = tagger.parse(text)
for n in word_s.split("\n"):
if n == 'EOS' or n == '': continue
p = n.split("\t")[1].split(",")
h, h2, org = (p[0], p[1], p[6])
if not (h in ['名詞', '動詞', '形容詞']): continue
if h == '名詞' and h2 == '数': continue
result.append(org)
return result
if not (h in ['名詞', '動詞', '形容詞']): continueではストップワードの除去。
その下のif文でも名詞に数詞が含まれる場合はスキップしている。
result.append(org)で形態素解析した単語の原型をresultに追加していくことでストップワードを除去し、テキストの単語をIDで表現する準備をする。
words_to_ids()関数
def words_to_ids(words, auto_add = True):
'''単語一覧をIDの一覧に変換する''' # --- (*4)
result =
for w in words:
if w in word_dic:
result.append(word_dic[w])
continue
elif auto_add:
id = word_dic[w] = word_dic['_id']
word_dic['_id'] += 1
result.append(id)
return result
add_text()関数のwords_to_ids(tokenize(text))の部分でtokenize()関数の返り値を引数にしているので、テキストからストップワードを除去し、単語の原型が格納されている配列を引数にしている。
ここでは引数の単語をIDに変換していく。
word_dic(単語辞書)にループで回ってきた単語が含まれていなければ辞書に追加し、新たにその単語に割り振られたIDをresultに追加、含まれていればその単語をキーとする値(ID)を取得しresultに追加。
これによりresultにテキストをIDで表現した配列が生成される。
calc_files()関数
if __name__ == '__main__':
add_text('雨')
add_text('今日は、雨が降った。')
add_text('今日は暑い日だったけど雨が降った。')
add_text('今日も雨だ。でも日曜だ。')
print(calc_files())
print(word_dic)
次にcalc_files()関数を見ていく。
この関数は全文章で出現する単語の頻度と全文章での希少性を掛け合わせることで文章ごとの単語の重要性を示すデータを返す関数。
def calc_files():
'''追加したファイルを計算''' # --- (*7)
global dt_dic
result =
doc_count = len(files)
dt_dic = {}
# 単語の出現頻度を数える --- (*8)
for words in files:
used_word = {}
data = np.zeros(word_dic['_id'])
for id in words:
data[id] += 1
used_word[id] = 1
# 単語tが使われていればdt_dicを加算 --- (*9)
for id in used_word:
if not(id in dt_dic): dt_dic[id] = 0
dt_dic[id] += 1
# 出現回数を割合に直す --- (*10)
data = data / len(words)
result.append(data)
# TF-IDFを計算 --- (*11)
for i, doc in enumerate(result):
for id, v in enumerate(doc):
idf = np.log(doc_count / dt_dic[id]) + 1
doc[id] = min([doc[id] * idf, 1.0])
result[i] = doc
return result
global dt_dicで関数内でのdt_dicの変更がそのままグローバル変数のdt_dicに反映される。
for words in files:でテキストをIDで表現し配列がそれぞれ格納されている二次元配列をループ。
np.zeros()で単語辞書の単語数を持つ配列を作成。
for id in words:でテキストをIDで表現したデータをループするので単語のIDをidに格納して処理していく。data[id]+=1でその文章中での単語の出現頻度をカウントする配列でIDの出現頻度をカウント。
used_word[id] = 1ではその文章で出現した単語IDを格納していく。一つの文章中に複数同じ単語が出現しても値は1。
for id in used_word:で出現した単語IDを取得して処理。dt_dic(文書全体での単語の出現頻度)に含まれていなければそのIDをキーとする要素を追加。dt_dic[id]+=1で加算。
result.append(data)で出現頻度を割合に直したデータをresultに格納。
idf = np.log(doc_count / dt_dic[id]) +1で文書の数から任意の全体での単語の出現頻度を割ることで出現した回数が多いものほど小さい値になる。np.log()はネイピア数(これは定数で2.7....)を底にもつ対数を返すもの。対数にすることで大小関係は変わらず0.0
~1.0で表現できるから?対数に変換する明確な理由はわからなかった。ただ、一旦TF-IDFの手法ではこうすると覚えておこう。
doc[id]=min([doc[id]*idf, 1.0])でdic[id](単語の出現頻度を割合で表記したもの)にidf(全体における単語の希少性)を掛け合わせることで全体の文章でのその単語の希少性を示した値にdic[id]を更新する。
result[i] = docで更新したdoc(出現頻度を割合で表現しているデータ)で更新し大元の各文章での単語の出現頻度を割合で表記したデータを作り替えている。
CNNでカタカナ文字の分類
MLPでの学習結果と見比べてみる。
hanamichi-sukusuku.hatenablog.com
上記の記事でMLPの簡単なモデルでの結果を出力している。

実行結果

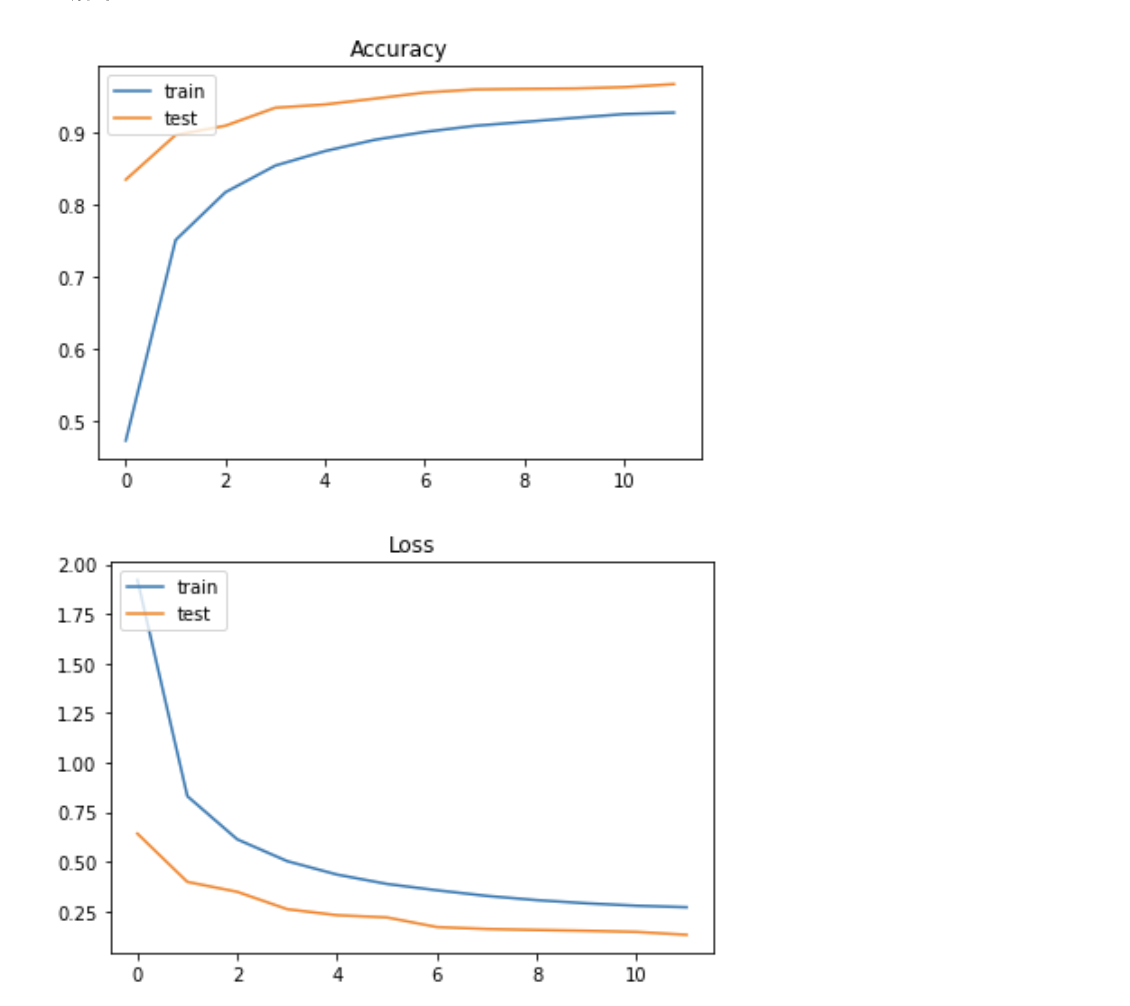
MLPでの評価結果は約90%だったのに対してCNNでの評価結果は約96%と高いものになった。
必要な値の定義と画像データの読み込み
import cv2, pickle
from sklearn.model_selection import train_test_split
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import RMSprop
from keras.datasets import mnist
import matplotlib.pyplot as plt
# データファイルと画像サイズの指定
data_file = "./png-etl1/katakana.pickle"
im_size = 25
out_size = 46 # ア-ンまでの文字の数
im_color = 1 # 画像の色空間/グレイスケール
in_shape = (im_size, im_size, im_color)
# カタカナ画像のデータセットを読み込む --- (*1)
data = pickle.load(open(data_file, "rb"))
im_sizeは今回扱う画像データは25✖️25なので25を定義しておく。
out_sizeはア~ンまでの数の46を定義。モデルの出力レイヤーのユニット数などに使用する。
im_colorはグレースケールのデータなので1を定義。RGB画像の場合は3。
in_shapeは今回のモデルには三次元の配列を扱うので1列の要素を25列持ち、それが25行の三次元配列によって一つの画像が表現されるので25(幅),25(高さ),1(色空間)の三次元の配列に変換する時に使用する。
pickle.load()で画像データ読み込み。
画像データの変形、ラベルデータone-hotベクトル化
y =
x =
for d in data:
(num, img) = d
img = img.astype('float').reshape(
im_size, im_size, im_color) / 255
y.append(keras.utils.to_categorical(num, out_size))
x.append(img)
x = np.array(x)
y = np.array(y)
読み込んだ画像データ(dataは(ラベルデータ,画像データ)このように格納されている)をreshape()で次元を変換する。既に25✖️25のまとまりでデータがループしてくるので25行,25列,1要素の三次元に変換。CNNのモデルを使うのでこの処理が必要。255で割ることで0.0~1.0で表現できるようにしている。
ラベルデータ(num)はkeras.utils.to_categorical()でone-hotベクトル化。46クラスに分類するので第二引数にout_sizeを指定。
学習用、テスト用に分割
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size = 0.2, train_size = 0.8, shuffle = True)
ここでx_train.shapeを実行してみると
(55309, 25, 25, 1)のように表示される。これは、(画像数, 画像幅, 画像高さ, 色数)の次元を持つ配列になっていることを表している。shapeでは各次元毎の要素数を確認することができる。
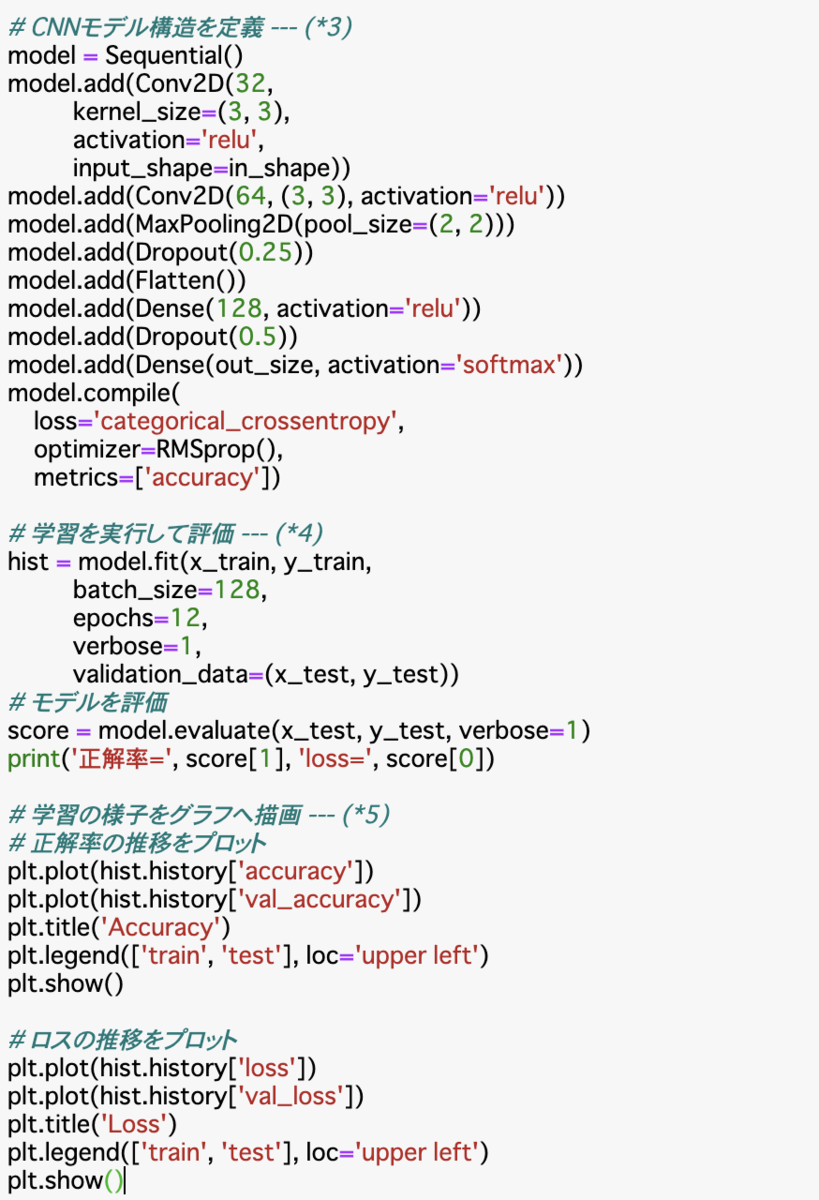
モデル構造の定義
model = Sequential()
model.add(Conv2D(32,
kernel_size=(3, 3),
activation='relu',
input_shape=in_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(out_size, activation='softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
Conv2Dは畳み込み層の作成。入力レイヤーのinput_shapeにin_shapeを指定することで三次元の入力を受け取ることができる。
流れとしては畳み込み、畳み込み、プーリング、ドロップアウト、平滑化、全結合層、ドロップアウト、出力レイヤーという流れでモデルを構築し、モデルをコンパイルしている。
学習を実行
hist = model.fit(x_train, y_train,
batch_size=128,
epochs=12,
verbose=1,
validation_data=(x_test, y_test))
batch_sizeは一度に計算するデータ量の指定。
epochsは何回繰り返し学習するか。
validation_dataで学習と同時に渡したデータのその時点での評価をhistoryオブジェクトに格納して返り値として受け取れる。
モデル評価
score = model.evaluate(x_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
学習の様子をグラフへ描画
# 正解率の推移をプロット
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# ロスの推移をプロット
plt.title('Loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
まとめ
・ETL文字データベースは日本語の手書きデータを数多く収録している。
・カタカナのように文字種類が多くても、画像データの種類が多ければ高い精度で文字認識を行うことができる。
・CNNを使うと学習に時間がかかるが判定精度は高い。